Variable not found
Procesar secuencias por lotes, o cómo usar chunks en C#
abril 23, 2024 06:05

Cuando tenemos una colección de datos para procesar, es relativamente habitual tener que hacerlo por lotes, es decir, dividir la colección en partes más pequeñas e irlas procesando por separado.
Para ello, normalmente nos vemos obligados a trocear los datos en lotes o chunks de un tamaño determinado, y luego procesar cada uno de ellos.
Por ejemplo, imaginad que tenemos un método que recibe una lista de objetos a procesar y, por temas de rendimiento o lo que sea, sólo puede hacerlo de tres en tres. Si la lista de elementos a procesar es más larga de la cuenta, nos veremos previamente obligados a trocearla en lotes de tres para ir procesando cada uno de ellos por separado.
Tradicionalmente, es algo que hemos hecho de forma manual con un sencillo bucle for que recorre la lista completa, y va acumulando los elementos en un nuevo lote hasta que alcanza el tamaño deseado, momento en el que lo procesa y lo vacía para empezar de nuevo.
Pero otra posibilidad bastante práctica, y probablemente más legible, sería pasar la lista de elementos previamente por otro proceso que retorne una lista de chunks, o pequeñas porciones de la lista original, para que luego simplemente tengamos que ir procesándolos secuencialmente. Es decir, algo así:
private char[] array = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'];
private int chunkSize = 3;
var chunks = GetChunks(array, chunkSize); // [['a', 'b', 'c'], ['d', 'e', 'f'], ['g', 'h', 'i'], ['j']
foreach (var chunk in chunks)
{
ProcessChunk(chunk); // 'chunk' sería un array de 3 elementos
}
Y la pregunta es, ¿cómo podríamos implementar ese método GetChunks() en C#? Vamos a ver varias opciones.
Primera: bucle simple
La primera opción que sin duda se nos vendrá a la cabeza será el típico bucle for que recorre la lista original y va acumulando elementos en un nuevo lote hasta que alcanza el tamaño deseado. En este momento, añade el chunk a la lista de lotes y lo vacía para empezar de nuevo.
Es una solución sencilla y eficaz, que podría implementarse más o menos como sigue:
public IEnumerable<char[]> GetChunks(char[] chars, int chunkSize)
{
var chunks = new List<char[]>();
var chunk = new List<char>();
for (int i = 0; i < chars.Length; i ++)
{
chunk.Add(chars[i]);
if (chunk.Count == chunkSize)
{
chunks.Add(chunk.ToArray());
chunk.Clear();
}
}
if (chunk.Any())
{
chunks.Add(chunk.ToArray());
}
return chunks;
}
Segunda: bucle simplificado
Partiendo de la opción anterior, y aprovechando que la secuencia de entrada es un array, podemos mejorar un poco el algoritmo para ir recorriendo la colección a saltos, en lugar de elemento a elemento, y usar los operadores de LINQ como Skip() y Take() para ir cogiendo los elementos que nos interesan:
IEnumerable<char[]> GetChunks(char[] chars, int chunkSize)
{
var chunks = new List<char[]>();
for (int i = 0; i < chars.Length; i += chunkSize)
{
var chunk = chars.Skip(i).Take(chunkSize).ToArray();
chunks.Add(chunk);
}
return chunks;
}
Tercera: todo a LINQ
Aunque la versión anterior ha simplificado bastante nuestro código, aún podemos hacerlo más legible y compacto haciendo uso de la potencia de LINQ. En este caso, podemos usar el método Select() para ir recorriendo la colección original y devolviendo un chunk de elementos en cada iteración. Observad que usamos GroupBy() para agrupar los elementos en lotes de tamaño chunkSize:
IEnumerable<char[]> GetChunks(char[] chars, int chunkSize)
{
return chars.Select((c, i) => new {c, i})
.GroupBy(x => x.i / chunkSize)
.Select(g => g.Select(x => x.c).ToArray());
}
Cuarta: LINQ simplificado con la cláusula Chunk()
Pues si ya creíamos haberlo visto todo con la opción anterior, esperaos a ver esta 😉 Resulta que con .NET 6 se introdujo en LINQ el método Chunk(), que básicamente hace lo que queremos: dividir los elementos de una sencuencia en fragmentos de un tamaño máximo.
Usándolo, nuestro método quedaría tan simple como esto:
IEnumerable<char[]> GetChunks(char[] chars, int chunkSize)
{
return chars.Chunk(chunkSize);
}
¿Y el rendimiento?
Pues la siguiente tabla, obtenida con nuestro amigo BenchmarkDotNet, nos muestra los resultados de las pruebas de rendimiento de cada uno de los métodos anteriores.
Como podéis ver, gana por paliza la última opción que hemos visto, la que utiliza Chunk(), pues es la que rinde mejor y ocupa menos memoria, con diferencia.
BenchmarkDotNet v0.13.12, Windows 11 (10.0.22631.3155/23H2/2023Update/SunValley3)
Intel Core i9-9900K CPU 3.60GHz (Coffee Lake), 1 CPU, 16 logical and 8 physical cores
.NET SDK 8.0.102
[Host] : .NET 8.0.2 (8.0.224.6711), X64 RyuJIT AVX2
DefaultJob : .NET 8.0.2 (8.0.224.6711), X64 RyuJIT AVX2
| Method | Mean | Error | StdDev | Gen0 | Allocated |
|------------------------- |-----------:|----------:|----------:|-------:|----------:|
| Fourth-LINQ-Chunk | 7.719 ns | 0.1662 ns | 0.2101 ns | 0.0086 | 72 B |
| Third-LINQ | 45.799 ns | 0.9308 ns | 2.2480 ns | 0.0315 | 264 B |
| Second-Simplified-Loop | 166.823 ns | 3.3372 ns | 5.7564 ns | 0.0715 | 600 B |
| First-Simple-Loop | 81.524 ns | 1.6638 ns | 1.5563 ns | 0.0334 | 280 B |
¡Espero que os haya resultado interesante!
Publicado en Variable not found.
Variable not found
Enlaces interesantes 565
abril 22, 2024 06:05

Ahí van los enlaces recopilados durante la semana pasada. Espero que os resulten interesantes. :-)
Por si te lo perdiste...
- Omisión condicional de propiedades al serializar con System.Text.Json
José M. Aguilar - Interpolación de cadenas en C# 6
José M. Aguilar
.NET Core / .NET
- Automated NuGet package version range updates in .NET projects using Renovate
Anthony Simmon - Improvements in the Using Directive for Additional Types in C#
Georgios Panagopoulos - The New C# Interceptors vs. AOP.
Marek Sirkovský - C# Optional Parameters Explained
NDepend Team - Linting and Code Formatting in .NET Projects
Hamed Shirbandi - 10 Advanced C# Tricks for Developers
Konstantin Fedorov - .NET 8 and C# 12 — Interceptors
Henrique Siebert Domareski - Streamline your container build and publish with .NET 8
Richard Lander - How to Use HttpOnly Cookie in .NET Core for Authentication and Refresh Token Actions
Marinko Spasojević - C# URI Concatenation
Bill Boga - Code It Any Way You Want: Checking Strings for Null
David McCarter - Computing code coverage for a .NET project
Gérald Barré - C# Regular Expression Benchmarks – How To Avoid My Mistakes!
Nick Cosentino - What’s New in .NET 8 for Developers?
Vinoth Kumar Sundara Moorthy - The Difference Between Invariance, Contravariance and Covariance in Generics in C#
Georgi Georgiev - Baseline Styling in BenchmarkDotNet
Januarius Njoku
ASP.NET Core / ASP.NET / Blazor
- Implement a secure Blazor Web application using OpenID Connect and security headers
Damien Bowden - Giving the .NET smart components a try–The Smart Combobox
Bart Wullems - Adjusting the Maximum Request Length for ASP.NET Core and ASP.NET Applications
Bjoern Meyer - Easily Render Flat Data in Blazor File Manager
Keerthana Rajendran - Build & test resilient apps in .NET with Dev Proxy
Waldek Mastykarz - Blazor Basics: Handling Images Dynamically
Claudio Bernasconi - ASP.NET Core–Cannot resolve
<Service>from root provider because it requires scoped service
Bart Wullems - Serilog and .NET 8.0 minimal APIs
Nicholas Blumhardt - ASP.NET Core - Use factory based middleware with scoped services
Bart Wullems - API Key Authentication Middleware In ASP NET Core
Nick Cosentino
Azure / Cloud
- Building your own copilot with a low-code approach: Azure AI Studio vs Copilot Studio
Carlotta Castelluccio
Conceptos / Patrones / Buenas prácticas
- TalkingBit: Mutation Testing
Fran Iglesias - What is Mocking? Mocking in .NET Explained With Examples
Grant Riordan - Modular Monoliths and the “Critter Stack”
Jeremy D. Miller
Data
- PostgreSQL: Announcing pl/dotnet, version 0.99 (beta)
Brick Abode - Snake draft sorting in SQL Server, part 1
Aaron Bertrand - Returning A Row When Your Query Has No Results
Erik Darling - A Clever Way To Implement Pessimistic Locking in EF Core
Milan Jovanović - ASP.NET Core Basics: Getting Started with LINQ
Assis Zang
Machine learning / IA / Bots
- Introducing Meta Llama 3: The most capable openly available LLM to date
Meta - How Microsoft discovers and mitigates evolving attacks against AI guardrails
Mark Russinovich - Data Anomaly Detection Using a Neural Autoencoder with C#
James McCaffrey
Web / HTML / CSS / Javascript
- JavaScript: la historia del lenguaje que cambió la web
José Manuel Alarcón - Angular Signal Queries: simplifying DOM querying
Davide Passafaro - Client Caching in SvelteKit
Jonathan Gamble - How to build an in-memory Message Bus in TypeScript
Oskar Dudycz - Rendering Math in HTML: MathML, MathML Core, and AsciiMath
Andrew Lock - Event Queues and Buffering Functions with JavaScript
Khalid Abuhakmeh - How To Monitor And Optimize Google Core Web Vitals
Matt Zeunert - HTML popover Attribute
David Walsh - Understanding Type Annotations in TypeScript
Stephen Akugbe - Front-end Framework: Comparing Bootstrap, Foundation and Materialize
Chizobam Favour - React JS Fragments
Vishnu Satheesh - The align-content property for block layouts is now part of Baseline
Rachel Andrew - Top Linters for JavaScript and TypeScript: Simplifying Code Quality Management
Nipuni Arunodi - Converting Plain Text To Encoded HTML With Vanilla JavaScript
Alexis Kypridemos - Top 5 Underutilized JavaScript Features
Loraine Lawson - Caching secrets of the HTTP elders, part 1
Cal Paterson - Upgrading jQuery: Working Towards a Healthy Web
Timmy Willison - Improving Code Quality in JavaScript Projects With Qodana
Ekaterina Trukhan - Demystifying Screen Readers: Accessible Forms & Best Practices
Chris DeMars - Help us invent CSS Grid Level 3, aka “Masonry” layout
Jen Simmons
Visual Studio / Complementos / Herramientas
- Exploring GitHub Copilot at Azure Developers JavaScript Day 2024
Glaucia Lemos - Stop Debugging and Start Running in Visual Studio
Steve Smith
.NET MAUI / Xamarin
- Sands of MAUI: Issue #141
Sam Basu - Create a Modern Conversational UI with the .NET MAUI Chat Control
Carter Harris - Apple Deployment/Distribution for .NET MAUI Apps
Sam Basu
Publicado en Variable not found.
Variable not found
Deserializar un objeto JSON a un diccionario .NET con System.Text.Json
abril 16, 2024 06:05

Hace poco vimos cómo serializar y deserializar datos en JSON de forma personalizada usando custom converters e implementamos un ejemplo simple capaz de introducir en campos de tipo int de .NET casi cualquier valor que pudiera venir en un JSON.
Pero como comentamos en su momento, la serialización y deserialización de objetos más complejos no es una tarea tan sencilla y requiere algo más de esfuerzo. En este post vamos a ver la solución para un escenario que creo que puede ser relativamente habitual: deserializar un objeto JSON a un diccionario Dictionary<string, object>.
En otras palabras, queremos que funcione algo como el siguiente código:
using static System.Console;
...
var json = """
{
"name": "Juan",
"age": 30
}
""";
var dict = ... // Código de deserialización
WriteLine($"{dict["name"]} tiene {dict["age"]} años"); // --> Juan tiene 30 años
Con
Newtonsoft.Json, la deserialización de un objeto JSON arbitrario a un diccionario genérico está contemplada de serie, por lo que no hay que hacer nada. Simplemente, funcionará:
using static System.Console;
...
var dict = JsonConvert.DeserializeObject<Dictionary<string, object>>(json);
object name = dict["name"];
object age = dict["age"];
WriteLine($"{name} tiene {age} años"); // --> Juan tiene 30 años
WriteLine("name es " + dict["name"].GetType()); // --> name es System.String
WriteLine("age es " + dict["age"].GetType()); // --> age es System.Int64
string n = (string)name;
System.Console.WriteLine(n); // --> Juan
Sin embargo, con System.Text.Json no es tan sencillo. Aunque esta biblioteca creará correctamente un diccionario cuyas claves se corresponderán con los nombres de las propiedades del objeto JSON, el convertidor por defecto para el tipo object deserializará los valores en objetos de tipo JsonElement, lo cual dificultará luego su manipulación. Podemos verlo en el siguiente código:
using static System.Console;
...
var dict = JsonConvert.DeserializeObject<Dictionary<string, object>>(json);
object name = dict["name"];
object age = dict["age"];
WriteLine($"{name} tiene {age} años"); // --> Juan tiene 30 años
WriteLine("name es " + dict["name"].GetType()); // --> name es System.Text.Json.JsonElement
WriteLine("age es " + dict["age"].GetType()); // --> age es System.Text.Json.JsonElement
string n = (string)name; // Boom! "InvalidCastException"
Para solucionarlo, debemos crear un convertidor personalizado para Dictionary<string, object> que sea capaz de deserializar al tipo apropiado cada valor del objeto JSON. Como vimos en el post anterior, la estructura básica del custom converter podría ser algo así:
public class ObjectDictionaryConverter : JsonConverter<Dictionary<string, object>>
{
public override Dictionary<string, object> Read(
ref Utf8JsonReader reader, Type typeToConvert, JsonSerializerOptions options)
{
// Aquí irá el código de deserialización
}
public override void Write(
Utf8JsonWriter writer, Dictionary<string, object> value,
JsonSerializerOptions options)
{
// En este caso vamos a implementar exclusivamente la deserialización,
// por lo que no necesitamos implementar el método Write
throw new NotImplementedException();
}
}
Centrémonos ahora en el código del método Read() que, como ya sabemos, es el encargado de leer el JSON e ir generando los datos equivalentes en objetos .NET. A nivel de código, podemos tener una primera versión simplificada como la siguiente:
public override Dictionary<string, object> Read(
ref Utf8JsonReader reader, Type typeToConvert, JsonSerializerOptions options)
{
if (reader.TokenType == JsonTokenType.StartObject)
{
var dictionary = new Dictionary<string, object>();
while (reader.Read())
{
if (reader.TokenType == JsonTokenType.PropertyName)
{
// Get the property name
var key = reader.GetString();
// Get the property value
reader.Read();
// Add the property to the dictionary
dictionary[key] = ReadValue(ref reader, options);
}
else if (reader.TokenType == JsonTokenType.EndObject)
{
return dictionary;
}
}
}
throw new JsonException("Invalid json format. Expected object.");
}
Lo que estamos haciendo es:
- Comprobar que el primer token del JSON es el carácter de apertura de un objeto (
{). - Tras ello, recorreremos el JSON leyendo primero el nombre de la propiedad.
- Por cada una de estas propiedades, obtendremos el valor .NET correspondiente y lo añadiremos al diccionario. El valor lo obtenemos llamando al método
ReadValue()que definiremos más abajo. - Cuando llegamos al final del objeto, devolvemos el diccionario.
Por otra parte, el método ReadValue() será el encargado de obtener el valor de la propiedad. Usaremos un switch que nos permita identificar el tipo de valor que estamos leyendo y actuar en consecuencia.
Comencemos con una implementación simple:
private object ReadValue(ref Utf8JsonReader reader, JsonSerializerOptions options)
{
switch (reader.TokenType)
{
case JsonTokenType.String:
return reader.GetString();
case JsonTokenType.Number:
if (reader.TryGetInt32(out int intValue))
{
return intValue;
}
else
{
return reader.GetDouble();
}
case JsonTokenType.True:
return true;
case JsonTokenType.False:
return false;
case JsonTokenType.Null:
return null;
default:
throw new JsonException($"Unexpected token type: {reader.TokenType}");
}
}
Esto es similar a lo que vimos en el post anterior: en función del tipo de token obtenido, creamos el objeto .NET correspondiente.
Soportando arrays y objetos anidados
Lo que hemos visto hasta el momento podría ser una primera versión aceptable que cubriría los escenarios más simples, pero tiene un par de problemas: no soporta que el valor de una propiedad sea un array, ni tampoco que sea un objeto JSON anidado. Es decir, funcionaría con un JSON plano como el que hemos visto antes, pero no con este caso:
{
"name": "Juan",
"age": 30,
"favoriteColors": ["rojo", "verde", "azul"],
"address": {
"street": "Sesame Street",
"city": "New York",
}
}
Si intentamos deserializar este JSON con el código anterior, fallará en tiempo de ejecución cuando intente deserializar el valor de la propiedad favoriteColors o address.
Vamos a solucionar el problema con los arrays. Para ello, necesitamos añadir otro caso al switch, de forma que contemplemos la posibilidad de que el valor de la propiedad sea un array, algo que detectamos fácilmente cuando el token leído es de tipo JsonTokenType.StartArray:
case JsonTokenType.StartArray:
var list = new List<object>();
while (reader.Read())
{
if (reader.TokenType == JsonTokenType.EndArray)
{
break;
}
list.Add(ReadValue(ref reader, options));
}
return list.ToArray();
Como podéis observar, cuando detectamos el inicio de un array, recorremos todos sus elementos y, por cada uno de ellos, de forma recursiva, llamamos a ReadValue()para obtener su valor.. Finalmente, devolvemos el array resultante en forma de object[].
Para contemplar el caso de los objetos JSON anidados, debemos añadir igualmente otro caso al switch que detecte el token de inicio de un objeto y llame recursivamente a Read() para obtener el diccionario correspondiente:
case JsonTokenType.StartObject:
return Read(ref reader, typeof(Dictionary<string, object>), options);
El código completo del convertidor personalizado
Pues para que lo tengáis todo a mano y poder echarle un vistazo completo, aquí tenéis el código del convertidor personalizado:
public class ObjectDictionaryConverter : JsonConverter<Dictionary<string, object>>
{
public override Dictionary<string, object> Read(
ref Utf8JsonReader reader, Type typeToConvert, JsonSerializerOptions options)
{
if (reader.TokenType == JsonTokenType.StartObject)
{
var dictionary = new Dictionary<string, object>();
while (reader.Read())
{
if (reader.TokenType == JsonTokenType.PropertyName)
{
// Get the property name
var key = reader.GetString();
// Get the property value
reader.Read();
// Add the property to the dictionary
dictionary[key] = ReadValue(ref reader, options);
}
else if (reader.TokenType == JsonTokenType.EndObject)
{
return dictionary;
}
}
}
throw new JsonException("Invalid json format. Expected object.");
}
private object ReadValue(ref Utf8JsonReader reader, JsonSerializerOptions options)
{
switch (reader.TokenType)
{
case JsonTokenType.String:
return reader.GetString();
case JsonTokenType.Number:
if (reader.TryGetInt32(out int intValue))
{
return intValue;
}
else
{
return reader.GetDouble();
}
case JsonTokenType.True:
return true;
case JsonTokenType.False:
return false;
case JsonTokenType.Null:
return null;
case JsonTokenType.StartArray:
var list = new List<object>();
while (reader.Read())
{
if (reader.TokenType == JsonTokenType.EndArray)
{
break;
}
list.Add(ReadValue(ref reader, options));
}
return list.ToArray();
case JsonTokenType.StartObject:
return Read(ref reader, typeof(Dictionary<string, object>), options);
default:
throw new JsonException($"Unexpected token type: {reader.TokenType}");
}
}
public override void Write(
Utf8JsonWriter writer, Dictionary<string, object> value,
JsonSerializerOptions options)
{
throw new NotImplementedException();
}
}
Una prueba rápida
Para probar el convertidor personalizado, podríamos usar un código como el siguiente, donde deserializamos un JSON complejo a un diccionario y luego accedemos a distintos valores:
using System.Text.Json;
using System.Text.Json.Serialization;
using static System.Console;
var json = """
{
"name": "Juan",
"age": 30,
"favoriteColors": ["red", "green", "blue"],
"address": {
"street": "123 Main St",
"city": "Springfield"
}
}
""";
var options = new JsonSerializerOptions();
options.Converters.Add(new ObjectDictionaryConverter());
var dict = JsonSerializer.Deserialize<Dictionary<string, object>>(json, options);
object name = dict["name"];
object age = dict["age"];
WriteLine($"{name} tiene {age} años"); // --> Juan tiene 30 años
WriteLine("name es " + dict["name"].GetType()); // --> name es System.String
WriteLine("age es " + dict["age"].GetType()); // --> age es System.Int32
WriteLine("colors: " + dict["favoriteColors"].GetType()); // --> colors: System.Object[]
object[] colors = dict["favoriteColors"] as object[];
WriteLine(colors[1]); // --> verde
var city = (dict["address"] as Dictionary<string, object>)["city"];
WriteLine(city); // --> Springfield
¡Espero que os sea de utilidad!
Publicado en Variable not found.
Variable not found
Enlaces interesantes 564
abril 15, 2024 06:05
Ahí van los enlaces recopilados durante la semana pasada. Espero que os resulten interesantes. :-)
Por si te lo perdiste...
- Breakpoints temporales y dependientes en Visual Studio 2022
José M. Aguilar - Expresiones lambda en miembros de función de C# 6
José M. Aguilar
.NET Core / .NET
- .NET 9 Preview 3
James Montemagno - Introducing MSTest SDK – Improved Configuration & Flexibility
Marco Rossignoli - Integer Overflow Vulnerabilities in .NET
Jason Sultana - Creating ico files from multiple images in .NET
Gérald Barré - The Best Way to Assign an Initial Value to Auto-Properties in C#
Kundar Kumar - C# Regex Performance: How To Squeeze Out Performance
Nick Cosentino - How to Retrieve the Number of CPU Cores in C#
Lennart Pries - Handling Circular References When Working With JSON in .NET
Georgios Panagopoulos - Equip 3rd party types with a deconstructor
Steven Giesel - How to Set a Default User-Agent on an HttpClient in ASP.NET Core
Mandar Dharmadhikari
ASP.NET Core / ASP.NET / Blazor
- BFF secured ASP.NET Core application using downstream API and an OAuth client credentials JWT
Damien Bowden - Introducing the New Blazor Timeline Component
Indrajith Srinivasan - Easily Customize the Toolbar in Blazor PDF Viewer
Kameshwaran R - Adding SignalR into ASP.NET
Brian Mullen - Blazor Basics: Templating Components with RenderFragments
Claudio Bernasconi - ASP.NET Core + Razor + HTMX + Chart.js
Howard van Rooijen - How to Test gRPC Services in ASP.NET Core
Aneta Muslić
Azure / Cloud
Conceptos / Patrones / Buenas prácticas
- 5 Rules for DTOs
Steve Smith - Actually Talking about Modular Monoliths
Jeremy D. Miller
Data
- Useful features in Entity Framework Core 8 for your application
Dennis Frühauff - 20 Essential Entity Framework Core Tips: Optimize Performance, Streamline Queries, and Enhance Data Handling
Sukhpinder Singh - DBCC CLONEDATABASE in Microsoft SQL Server
Madhumita Tripathy
Machine learning / IA / Bots
- Hands-on Gemini 1.5 Pro with AI Studio: Images, Video, Text & Code
Addy Osmani - Build a serverless ChatGPT with RAG using LangChain.js
Yohan Lasorsa - Using Handlebars Planner in Semantic Kernel
Sophia Lagerkran - Semantic Kernel Hello World Plugins Part 1-Jason Haley's Blog
Jason Haley - Using keyless authentication with Azure OpenAI
Pamela Fox
Web / HTML / CSS / Javascript
- Overview of webpack, a JavaScript bundler
John Reilly - Demystifying the Shadow DOM
Petar Ivanov - What’s New in Syncfusion Essential JS 2: 2024 Volume 1
Sumankumar G. - 3 simple design tips to improve your Web UI
Jon Hilton - @ and */ in JavaScript Multiline Comments
Hamidreza Mahdavipanah - Browser Security Bugs that Aren’t: JavaScript in PDF
Eric Lawrence - React Server Components in a Nutshell
Loraine Lawson - The difference between '||' and '??' in JavaScript
Emmanuel - Your background images might be causing CLS
Salma Alam-Naylor - Sliding 3D Image Frames In CSS
Temani Afif - Quick Tip: How to Animate Text Gradients and Patterns in CSS
Ralph Mason - Testing Signals with Angular Testing Library
Tim Deschryver - Old CSS, new CSS / fuzzy notepad
Eeve
Visual Studio / Complementos / Herramientas
- Git: ¿qué diferencia hay entre un tag anotado y uno ligero?
CampusMVP - Introducing the new Copilot experience in Visual Studio
Rhea Patel - Creating Tests with GitHub Copilot for Visual Studio
Laurent Bugnion
.NET MAUI / Xamarin
- Introducing Syncfusion .NET MAUI Visual Studio Code Extension
Jose Seeron Anthony Pitchai
Otros
- Hello world
Lennon McLean
Publicado en Variable not found.
Metodologías ágiles. De lo racional a la inspiración.
Scrum master a tiempo completo: 42 Tareas
abril 11, 2024 08:26
Metodologías ágiles. De lo racional a la inspiración.
CAS2017: Conferencias Agile-Spain
abril 11, 2024 08:24
Picando Código
Más experimentos con DragonRuby
abril 10, 2024 08:50
Desde que empecé mi aventura con DragonRuby, programando una implementación de Tetris, seguí jugando con la herramienta. Todas las semanas he ido pensando cosas divertidas para programar. Generalmente se me ocurría alguna visualización en particular, o veía algo que me hacía pensar “¿cómo se implementará eso en DragonRuby?”, y me desafiaba a hacerlo.
Seguí con la tendencia que empecé escribiendo Tetris: no buscar si ya existía una forma ya conocida de hacer algo, sino implementarlo de cero. Esto me obligaba a aprender cosas nuevas e intentar entenderlas a nivel más bajo. DragonRuby ofrece un montón de aplicaciones de ejemplo y muestras de cómo hacer muchas cosas que generalmente necesitaríamos programar en un videojuego. Pero todavía no las he investigado. Sólo busqué en la documentación las APIs que necesitaba. Por ejemplo, después de implementar un menú de selección de dos filas, donde implementé la navegación y qué pasa si navego a la derecha cuando estoy en el borde derecho, etc., me enteré que existía una API de geometría.
Así que terminé haciendo una nueva aplicación con experimentos que fueron evolucionando desde una idea básica a ser programados. Hay un poco de todo, pero más que nada son pruebas para lograr visualizaciones a través de funciones matemáticas y “cómo se lograría esto con DragonRuby”. Pero no tienen mucho en común más que yo experimentando y programando cosas que quiero programar. Hasta la introducción es una referencia a algo que vi en una película y me dije “Esto sería divertido implementar en DragonRuby”.
Algunas cosas me resultaron relativamente sencillas, otras las tuve en la cabeza rumeando por días hasta que me salieron (te estoy mirando experimento con partículas). Me acuerdo muy poco de matemática del liceo, pero seguro lo hubiera aprendido con más ganas si me lo enseñaban orientado a programación gráfica. Igual estuvo bueno volver a aprender cosas o llegar a la fórmula de algo pensándolo hasta que me saliera humo de las orejas por sobrecalentamiento del cerebro. Fue un desafío bienvenido y entretenido. De nuevo me encontré con esa motivación con la programación que comentaba en el post sobre Tetris: momentos en los que soltaba lo que estaba haciendo o me quedaba hasta tarde para arreglar algún bug, agregar un experimento nuevo o agregarle más cosas a lo que ya había.
Todavía tengo algunas ideas más para agregarle, pero me imagino que lo mantendré como un repositorio para probar cosas y experimentar con la herramienta. Lo subí a itch.io, y se puede descargar en Linux, Windows, Mac OS y Raspberry Pi. Pero también se puede ejecutar online desde la página en Itch:
DragonRuby Experiments by picandocodigo
Con el teclado, mouse o un gamepad conectado a la computadora se puede elegir en el menú principal uno de los experimentos y presionar enter, hacer clic o el botón “A”. Los paneles que muestran una ola, una grilla y un arcoíris son animaciones generadas a código pero no se puede interactuar con ellas. La tecla F del teclado cambia a pantalla completa (o salir si ya se está en ese modo). A continuación listo los comandos al momento de escribir esto, pero posiblemente cambien con el tiempo. Mi idea es agregar un menú con ayuda para cada visualización para ver la lista de comandos posibles.
El experimento del medio en la fila superior, que llamé “hyperspace”, tiene varias acciones que se disparan con botón derecho/izquierdo del mouse, las flechas arriba y abajo del teclado (o rueda del mouse para arriba/abajo) las teclas I y barra de espacio en el teclado o los botones del Gamepad. La vizualisación de la fila inferior al borde izquierdo simula estática en un televisor de tubo de rayos catódicos con el código más ineficiente posible, jeje. Podemos alterar la intensidad de la estática con las flechas arriba y abajo del teclado. Por último, el experimento en el borde derecho de la fila inferior usa las teclas para arriba y abajo (o rueda del mouse), las teclas A, Z, S, X y espacio del teclado, los botones derecho e izquierdo del mouse y los botones del Gamepade (incluyendo el Start).
Dejo al usuario descubrir qué hace cada cosa si prueba el experimento.
Le agregaré algo más, pero ya es hora de ponerme a mirar esas documentaciones y aplicaciones de muestra y desarrollar un juego original…
El post Más experimentos con DragonRuby fue publicado originalmente en Picando Código.Variable not found
¿Podría Blazor llegar a reemplazar a MVC?
abril 09, 2024 06:30

Este tema lo he debatido con colegas en varias ocasiones y creo que abordarlo aquí puede resultar interesante para algunos más que os estéis preguntando lo mismo a raíz de la tracción que, poco a poco, va tomando Blazor entre los desarrolladores web que trabajamos con el stack de tecnologías de Microsoft.
Voy a explicar mi punto de vista al respecto contemplando dos aspectos distintos, que creo que son los fundamentales para poder responder apropiadamente a esta pregunta:
- Si técnicamente sería posible reemplazar MVC por Blazor, esto es, si Blazor dispone de mecanismos suficientes para cubrir las necesidades de una aplicación que tradicionalmente se desarrollaría con MVC.
- Si la popularidad y difusión de Blazor podría llegar a alcanzar las cotas suficientes para convertirse en una alternativa completa y segura a MVC, en términos de madurez, estabilidad, soporte y tamaño de la comunidad. O en otras palabras, si Blazor como producto llegará a estar lo suficientemente consolidado como para poder reemplazar a MVC.
Vamos a analizar cada una de ellas.
Disclaimer: obviamente, todo lo que veréis a continuación son opiniones personales y, como tales, pueden ser discutibles. Si tenéis una opinión diferente, estaré encantado de leerla en los comentarios.
¿Es técnicamente viable reemplazar MVC por Blazor?
Hasta ASP.NET Core 8, Blazor estaba enfocado exclusivamente al desarrollo de aplicaciones Single Page Application (SPA), es decir, aplicaciones web que se ejecutan por completo en el navegador y que frecuentemente se comunican con un servidor para obtener datos y servicios. En este sentido, Blazor era una alternativa a Angular, React o Vue, entre otros, y no a frameworks de backend como ASP.NET Core MVC o Razor Pages. Simplemente, jugaban en ligas distintas.
Sin embargo, con la llegada de las Blazor Web Apps en ASP.NET Core 8, la cosa ha cambiado bastante. Blazor ahora puede utilizarse para desarrollar aplicaciones web tradicionales, en las que el código se ejecuta en el servidor, enviando el resultado HTML al navegador. Vaya, como los frameworks de backend de toda la vida.
Gracias a esta nueva posibilidad, denominada Server-Side Rendering, Blazor puede cubrir un espectro de aplicaciones web mucho más amplio, y probablemente podría reemplazar a MVC sin problema. De hecho, en muchos aspectos, Blazor puede ser una opción más atractiva para muchos desarrolladores debido a su facilidad de uso y la productividad que proporciona su modelo de componentes, a algunas funcionalidades chulas (como el stream rendering o la navegación mejorada) y porque en muchos casos podría eliminar el JavaScript que necesitamos para implementar funcionalidades habituales funcionalidades en cliente (de hecho, es rara la aplicación MVC que no tenga que usar JavaScript para añadir funcionalidades en frontend).
Técnicamente, en aplicaciones web, Blazor podría reemplazar por completo a las capas "V" y "C" de "MVC", es decir, la Vista y el Controlador. El Modelo podría seguir siendo el mismo, porque ni Blazor ni MVC son prescriptivos en este sentido.
Una de las principales ventajas de Blazor respecto a MVC para la implementación de estas capas es su sencillez. En MVC, a veces resulta tedioso tener que crear y gestionar tantos artefactos para realizar tareas simples; por ejemplo, crear un controlador, una acción y una vista (en su carpeta correspondiente por convención) para mostrar una página sería mucho más sencillo en Blazor, donde crearíamos un único archivo que une la interfaz y la lógica de presentación.
MVC, gracias a su madurez, había ido incorporando herramientas para mejorar nuestra productividad durante la creación de vistas y componentes de interfaz, como los layouts, tag helpers, html helpers, view components, partial views o secciones. Todos ellos tienen su equivalente en Blazor, así que el salto a esta tecnología no supone la pérdida de estas funcionalidades.
Pero además, el modelo de componentes de Blazor es una pasada, y cuando empezamos a trabajar con él nos hace sentirnos especialmente productivos por lo fácil que resulta crearlos y reutilizarlos.
Tanto en MVC como en Blazor, el sistema de routing corre sobre la misma infraestructura (el sistema de routing de ASP.NET Core), por lo que en la mayoría de los escenarios podremos lograr lo mismo. Las páginas creadas con Blazor declaran sus propias rutas que, como en los demás casos, pueden contener porciones parametrizables y restricciones (constraints) predefinidas o personalizadas.
Blazor también proporciona su sistema de binding, que permite enlazar datos con la interfaz de usuario de forma muy sencilla gracias al uso del patrón MVVM. A la hora de escribir formularios, se utilizan las mismas data annotations que en MVC para validaciones automáticas y, por tanto, disponen de los mismos mecanismos de extensibilidad.
También es posible inyectar dependencias en los componentes de Blazor, lo que nos permite seguir trabajando con el patrón al que ya estamos acostumbrados al usar MVC.
Pero bueno, tampoco es oro todo lo que reluce 😉 Hay características de MVC que no pueden ser implementadas en Blazor, o al menos de forma sencilla.
Por ejemplo, en Blazor no disponemos de filtros (al menos no en el sentido en el que los usamos en MVC). No podemos controlar muy detalladamente las peticiones entrantes (por ejemplo, definir distintos manejadores en función del verbo HTTP), pero no lo necesitaremos para los objetivos de Blazor. Tampoco tenemos tipos de resultado distintos (IActionResult de MVC), caché de resultados integrado, o control fino sobre las respuestas como podríamos tener con este marco de trabajo.
La implementación o configuración de un sistema de autenticación no está demasiado bien resuelta de momento. Aunque previsiblemente esto mejorará en la siguiente versión (noviembre), Blazor en ASP.NET Core 8 viene algo cortito en esto, principalmente debido a los modelos de hosting y la forma en que pueden coexistir en los proyectos.
Y, por supuesto, Blazor no nos valdrá para crear APIs: no es su misión. Para eso, tendremos que seguir recurriendo a MVC o a las minimal APIs.
Bueno, probablemente se me escapen cosas, pero creo que con lo comentado hasta el momento ya podríamos ver que MVC sería técnicamente reemplazable por Blazor en muchos escenarios. Es decir, hay aplicaciones que podríamos escribirlas indistintamente usando cualquiera de las dos opciones.
Pero aparte, Blazor ofrece posibilidades fuera del alcance de MVC, que tradicionalmente teníamos que complementar usando JavaScript. Con Blazor no sólo renderizaremos el HTML en el servidor, sino que podremos implementar ricos componentes interactivos ejecutados en el navegador, usando únicamente (o como mínimo, principalmente) C#.
¿Blazor se acabará ganando la confianza de los desarrolladores?
Está claro que, a día de hoy, Blazor no está tan difundido ni es tan popular como otras opciones con más trayectoria, y esto podría introducir un cierto grado de desconfianza a la hora de apostar en él para sustituir a nuestro querido MVC.
Hay que tener en cuenta que Blazor SSR, lo que técnicamente podría ser la alternativa real a MVC, lleva con nosotros sólo unos meses y, por tanto, no hemos tenido tiempo apenas para conocer todo su potencial y tomarle cariño 😉. Las versiones de Blazor disponibles hasta el momento competían en el mundo de las SPA (Angular, React...) y, por tanto, no eran equiparables a MVC ni podría haber optado nunca a reemplazarlo.
Salvo que tengamos una bola de cristal bien pulida, es imposible predecir el futuro y saber qué ocurrirá, así que de momento lo único que podemos hacer es interpretar las señales:
- Está claro que la apuesta de Microsoft por Blazor es fuerte, y viene demostrando en las últimas versiones de ASP.NET Core lanzadas. La cantidad de novedades (y, por tanto, entiendo que recursos dedicados) a Blazor es muy superior a las que van apareciendo en otros frameworks tradicionales como MVC o Razor Pages.
- Sigue habiendo grandes planes para el futuro. Si a día de hoy echamos un vistazo al roadmap de ASP.NET Core 9 (previsto para noviembre de 2024), podremos comprobar que la mayoría de features pertenecen a Blazor.
- Oficialmente, Blazor es la opción recomendada para la mayoría de escenarios de interfaz de usuario web (ver entrada de Microsoft Learn o comentario de Dan Roth al respecto).
- La comunidad de desarrolladores Blazor está creciendo, y cada vez hay más gente trabajando ya e interesada en aprenderlo, lo que se traduce en más contenidos, más bibliotecas, más ejemplos, más frameworks y más herramientas, tanto proporcionadas por Microsoft como por terceros. Aunque, por supuesto, de momento su popularidad sigue siendo inferior a lo que podemos encontrar en otros marcos de trabajo.
- El ámbito de aplicación de Blazor sigue creciendo. Quizás lo más visible últimamente ha sido la introducción de las Blazor Web Apps y el modelo unificado de componentes, que ha permitido a Blazor no sólo enfocarse al desarrollo de aplicaciones SPA, sino también al de las aplicaciones web tradicionales ejecutadas en servidor. Y no hay que olvidar su potencial uso en otros entornos, como aplicaciones de escritorio o móviles.
- Aunque se ha complicado un poco últimamente, la facilidad de aprendizaje y uso de Blazor es bien conocida. La curva de aprendizaje es relativamente suave, y muchos desarrolladores que ya conocen la web, C# y .NET pueden empezar a trabajar con Blazor en poco tiempo, especialmente los desarrolladores ASP.NET Core MVC y Razor Pages, porque ya conocen la sintaxis Razor, usada en componentes Blazor. Esto es un factor clave para que la adopción de la tecnología aumente.
- Creo que ya ha desaparecido el fantasma "Silverlight". El lastre de esta difunta tecnología persiguió a Blazor desde sus inicios, porque muchos desarrolladores pensaron que podrían seguir una trayectoria similar. Afortunadamente, creo que ya ha quedado claro que son cosas distintas, y que el momento es distinto también (recordemos que Silverlight fue una víctima de su tiempo, como otras tecnologías similares que coexistieron con él, como Flash o los Applets Java).
A la vista de esto, todo apunta a que Blazor podría llegar a convertirse en un producto consolidado y una alternativa real a MVC en un futuro quizás no muy lejano. Pero como decía antes, no hay certezas, y habrá que esperar a ver cómo evoluciona la tecnología y su grado de adopción en la industria.
En conclusión
Atendiendo a la mayoría de estos aspectos, parece que Blazor tiene un futuro prometedor y, por todo lo que hemos comentado antes, tiene potencial para reemplazar a MVC en muchos escenarios.
En cualquier caso, esto no implicaría la desaparición de MVC o Razor Pages, ni mucho menos. Se trata simplemente de disponer de opciones, poder elegir entre distintos caminos para llegar a un mismo destino: la construcción de aplicaciones web. También hay que tener en cuenta que Blazor no cubre necesidades frecuentes, como la construcción de APIs, algo para lo que tendríamos que seguir recurriendo a MVC o minimal APIs, por lo que estos marcos de trabajo seguirán siendo necesarios. La elección de uno u otro dependerá de las necesidades concretas de cada proyecto, posibilidades de reutilización de otros proyectos, las preferencias del equipo de desarrollo, la experiencia previa y de otros muchos factores.
Pero en mi opinión, la evolución de todo esto, al menos a corto-medio plazo, será la convivencia. Por suerte, Blazor, MVC, Razor Pages, minimal APIs y otros frameworks basados en ASP.NET Core están diseñados para trabajar bien juntos, y no hay nada que impida mezclarlos en un mismo proyecto si es lo que necesitamos. De hecho, esto permitiría a los equipos de desarrollo elegir la tecnología que mejor se adapte a cada parte de la aplicación o en la que puedan ser más productivos, y no tener que ceñirse a un único framework para todo.
Y vosotros, ¿qué opináis? ¿Creéis que Blazor podría reemplazar a MVC en un futuro? ¿O pensáis que MVC seguirá siendo la opción preferida para muchos desarrolladores? ¡Espero vuestros comentarios!
<Spam>Por cierto, si os estáis planteando aprender Blazor, ya estáis tardando en echarle un vistazo a mi curso de Blazor en CampusMVP. Pero si preferís MVC, también podéis poneros las pilas con mi curso Desarrollo de aplicaciones Web con ASP.NET Core y MVC😉</Spam>
Publicado en Variable not found.
Variable not found
Enlaces interesantes 563
abril 08, 2024 06:05
Ahí van los enlaces recopilados durante la semana pasada. Espero que os resulten interesantes. :-)
Por si te lo perdiste...
- ¿No te gusta que tus nuevos proyectos .NET usen top level statements? Pues Visual Studio y la CLI te lo ponen fácil
José María Aguilar - Interpolación de cadenas en C# 6
José María Aguilar
.NET Core / .NET
- Leer mensajes de un buzón de Office 365 con C# & Console application vs worker service
Sergio León - Getting the Method Name from a Task in C#
Bryan Hogan - Fastest Way to Check if a List is in Order in C#
Jeff Shergalis - Collection Initializer Performance in C#
Nick Cosentino - Easily navigate code delegates
Mark Downie - The .editorconfig files for .NET developers
NDepend - Json schema validation in .NET
Gérald Barré - Pattern matching and the compiler can be surprising
Steven Giesel - How to use xUnit to run unit testing in .NET and C#
David Grace - How to Validate a GUID in C#
Osman Sokuoglu - Enable tab completion for the .NET CLI in your terminal
Anthony Simmon - Testing Your Native AOT Applications
Marco Rossignoli - 24 Essential Async/Await Best Practices for Basic to Advanced C# Developers
Sukhpinder Singh - Just for Fun: A Five-Card Poker Library Using C#
James McCaffrey - Convert Excel to PDF in Just 5 Steps Using C#
Mohan Chandran - Examples of Composition in C# – A Simple Guide for Beginners
Nick Cosentino - Primary Constructor and Logging Don't Mix
Adam Storr
ASP.NET Core / ASP.NET / Blazor
- Mejorando la Observabilidad en ASP.NET Core con OpenTelemetry y Aspire
Isaac Ojeda - Blazor 8 Render Mode Detection
Rockford Lhotka - Blazor Basics: Improved Performance with Component Virtualization
Claudio Bernasconi - How to securely reverse-proxy ASP.NET Core web apps
Anthony Simmon
Azure / Cloud
- Configure Azure Functions to use Identity Based Connections
Mark Heath - Why do Azure Resource Groups have an Azure Region association?
Chris Pietschmann - Using Kudu in Azure to Debug an Azure Function
Paul Michaels - Unlocking Possibilities: Introducing Sidecar Pattern and Webjobs for Linux App Service in Public Preview!
Tulika Chaudharie
Conceptos / Patrones / Buenas prácticas
- Qué es una Entidad de Domain Driver Design y cómo se implementa en
Albert Capdevila - Thoughts on “Modular Monoliths”
Jeremy D. Miller - Not everything is a service.
Derek Comartin - A Brief History of Airbnb’s Architecture
ByteByteGo
Data
- SQL Server Filtered Index Essentials Guide
Simon Liew - C# MongoDB Insert Benchmarks – What You Need To Know
Nick Cosentino
Machine learning / IA / Bots
- Detecting Hallucinations in Large Language Models with Text Similarity Metrics
Rutam Bhagat - Making AI powered .NET apps more consistent and intelligent with Redis
Catherine Wang - Announcing cost-effective RAG at scale with Azure AI Search
Pablo Castro
Web / HTML / CSS / Javascript
- 10 Сustom Utility Types for TypeScript Projects
Anton Zamay - Tiny Predictive Text
Adam Grant - 10 Tips to Maximize Productivity in Tailwind CSS
Mario Yohan - Responsive Images Crash Course for ASP.NET Core Developers
Khalid Abuhakmeh - Infinite-Scrolling Logos In Flat HTML And Pure CSS
Silvestar Bistrović - Lazy load an iframe
Phuoc Nguyen - How to remove background of image with CSS
Madhu Saini - JavaScript String Methods That Make Developer’s Life Easier
Shalitha Suranga - A Full-Stack Web App Using Angular and GraphQL: Adding Login and Authorization Functionalities (Part 5)
Ankit Sharma - Understanding RegExp Capture Groups When Using .split() In JavaScript
Ben Nadel - Tips and Tricks to Make Your Web Apps Blazing Fast
Thomas Findlay - Introducing the New React Timeline Component
Senthilarasu Balu - Clawject: Simplifying Dependency Injection in TypeScript
Artem Korniev - Managing User Focus with :focus-visible
Chris DeMars
Visual Studio / Complementos / Herramientas
- How GitHub monopolized code hosting
Graphite - Syncing a git branch between Windows and WSL filesystems
Andrew Lock - The Visual Studio UI Refresh has made me more productive
Matt Lacey - Managing NuGets in VS Code
David Ortinau - How to Install GitHub Copilot in Visual Studio
Laurent Bugnion - How to use Comments to Prompt GitHub Copilot for Visual Studio
Gwyneth Peña-Siguenza
.NET MAUI / Xamarin
- .NET Meteor Update - New Level of Productivity for .NET MAUI in VS Code
Nikita Romanov - Xamarin Days Are Numbered—Ready to Migrate to .NET MAUI?
Yoan Krumov - .NET MAUI – Styles
Vijay Anand
Otros
- Java 22: todas las novedades
CampusMVP - Where Did My Traffic Go? Hint: It Wasn’t an Algorithm Update
Erik Dietrich
Publicado en Variable not found.
Arragonán
Reduciendo riesgos con tests de carga
abril 04, 2024 12:00
Hace varias semanas estuve involucrado en realizar algunos tests de carga en Genially, algo que no había tenido necesidad de hacer desde que trabajé en Inditex lanzando un nuevo servicio interno.
Esto venía dado por unos cambios en los que estuvimos trabajando un par de equipos para mejorar la experiencia de uso de una parte del producto, lo cual implicó un cambio bastante importante a nivel de arquitectura.
Con estos cambios teníamos 2 riesgos:
- Que aunque la experiencia de uso de la funcionalidad mejorase esto pudiera impactar negativamente en un funnel de conversión.
- Que la nueva solución que habíamos implementado pudiera causar problemas dependiendo de la carga y tuviéramos incidencias.
El primer riesgo lo minimizamos realizando un rollout incremental, que es como lanzamos la mayoría de cambios relevantes en Genially. Esto, en este caso, significó lanzar los cambios internamente bajo una feature flag para obtener feedback cualitativo y luego abrirlo a un porcentaje del tráfico para observar las métricas de producto.
El segundo riesgo, como mencionaba al principio, lo minimizamos realizando algunos tests de carga.
¿Pero qué es un test de carga?
Es un tipo de prueba en la que se genera tráfico de forma artificial para evaluar la respuesta o capacidad de un sistema ante una carga determinada de trabajo o de personas usuarias, por lo que puede servir para comprobar tanto el rendimiento como el escalado de un sistema.
Para esto, antes de ejecutar la prueba, necesitamos tener definido previamente qué y cómo lo vamos a observar para poder consultarlo tras su ejecución (tiempos de respuesta, consumo de recursos, etc). Así que el entorno sobre el que vayamos a probar tiene que ser observable; en este caso, lo que más nos va a interesar son las métricas y, en caso de que empiece a degradarse el servicio, también las trazas pueden ayudar a identificar el origen del problema con mayor facilidad.
En ocasiones, este tipo de pruebas se tienden a hacer con personas reales de manera algo informal, en plan “entrad aquí X personas a hacer Y metiéndole caña y vamos a ver cómo van las métricas Z”. Eso puede ser perfectamente válido para tener una idea general de cómo responde el sistema con una carga un tanto aleatoria, pero tiene el problema de que no es repetible ni controlado, por lo que de ese modo no podemos dar seguimiento a los resultados obtenidos de forma consistente.
Para tener consistencia en este tipo de pruebas, hay herramientas que nos permiten automatizarlas, de ese modo obtenemos escenarios controlados y repetibles a los que sí podemos dar seguimiento. Con estas herramientas, podremos definir distintos escenarios en los que queremos probar el sistema y observar si se mejora o empeora comparando los resultados de antes y después de un cambio.
En cuanto a herramientas concretas, en el pasado usé Apache HTTP Server Benchmarking Tool y JMeter, pero en la última ocasión lo hice con k6 por recomendación de mi compañero Manu Franco. La verdad es que me pareció una herramienta fácil de empezar a usar, y viendo su documentación también muy potente, así que de momento se ha convertido en mi preferencia.
Tipos de tests de carga
Dentro de los tests de carga, se pueden clasificar en subtipologías dependiendo del objetivo de la prueba y del patrón de generación de tráfico utilizado. Me gusta mucho la gráfica y la explicación de la propia documentación de k6.

- Smoke tests: son pruebas sobre el sistema de corta duración (segundos o pocos minutos) con una carga baja, con el objetivo de comprobar que todo funciona razonablemente bien sin consumir muchos recursos. De primeras, no los hubiera incluido como test de carga, pero dada la aproximación de esta herramienta de generar tráfico concurrente, les compro el incluirlo. En este caso, se podrían lanzar de forma bastante recurrente para detectar errores de configuración a nivel de aplicación o anomalías en las métricas de forma temprana.
- Average-load test: son pruebas sobre el sistema de duración media (minutos-hora) con una carga similar a la habitual, con el objetivo de asegurar que los cambios introducidos no impactan negativamente en el contexto habitual del sistema. Esto podría hacerse de forma periódica para encontrar potenciales problemas que se hayan podido introducir.
- Stress test: son pruebas sobre el sistema de duración media (minutos-hora) con una carga por encima de la habitual, con el objetivo de comprobar el comportamiento del sistema con un tráfico bastante superior al habitual. Esto nos puede ser útil, por ejemplo, para prepararnos para campañas como navidad o rebajas en el mundo del comercio electrónico.
- Spike test: de duración corta (unos pocos minutos) con una carga que sobrepase mucho la habitual del sistema. Su objetivo es ver cómo se comporta con un pico de tráfico masivo durante un tiempo más limitado. Escenarios para los que esto puede ser útil pueden ser prepararse para las primeras horas del Black Friday, si se va a lanzar un anuncio en prime time en televisión, etc.
- Breakpoint test: de duración indeterminada y una carga incremental hasta llegar a que el sistema se rompa o llegue al límite que hayamos definido. En este caso, el objetivo es llevar el sistema al extremo máximo para conocer en qué momento nuestro sistema no da más de sí o hasta dónde permitimos escalarlo si la infraestructura del sistema puede ir hacia “infinito”. Los escenarios podrían ser comprobar optimizaciones de partes del sistema o trabajar en un plan de contingencia si en algún momento el sistema se acerca a su límite.
- Soak tests: de larga duración (varias horas) y una carga similar a la habitual. Su objetivo es detectar problemas surgidos a partir de un uso extendido del sistema, como el aumento del consumo de infraestructura o la degradación de los tiempos de respuesta. Esto nos puede interesar especialmente cuando no somos los dueños de la infraestructura en la que corre nuestro sistema y queramos comprobar que quienes lo vayan a operar no se encuentren sorpresas posteriormente.
¿Cómo lanzar los tests de carga?
En un mundo ideal lo probaríamos en algún entorno aislado que se asemeje mucho a producción a nivel de infraestructura, pero no siempre podremos contar con esa posibilidad. Y la frencuencia de ejecución dependerá de cada contexto.
Por ejemplo, cuando trabajaba en Inditex, disponíamos de un entorno específico para este tipo de pruebas. Y dado que no era posible realizar llamadas entre entornos distintos debido a que estaba limitado a nivel de red, sabíamos que podíamos probar nuestros servicios de forma aislada sin necesidad de coordinarnos con equipos no involucrados en estas pruebas.
Por otro lado, para llevar a cabo pruebas preliminares del cambio de arquitectura al que me refería en Genially, las estuvimos realizando en un entorno efímero. A nivel de infraestructura, estos entornos efímeros son bastante limitados en comparación con el de producción, pero nos permitía realizar algunas validaciones en un entorno aislado también sin necesidad de coordinación. Utilizamos este entorno para ejecutar una serie de smoke tests y un mini average-load test para obtener las métricas base. Luego introdujimos los cambios relevantes y comprobamos si surgía alguna anomalía para ver si había que iterar algo, una vez visto que no había nada raro podíamos ir a producción con mayor confianza y darle seguimiento al uso real de las primeras horas.
En los casos que describo lanzábamos las pruebas de forma manual y luego analizábamos los resultados. Pero también existen contextos donde estas pruebas se lanzan automáticamente incluso en pipelines de continuous delivery. Así que se puede echar para atrás una release si un test falla dado el límite marcado como aceptable en una métrica. Por ejemplo si dada una carga se supera el máximo de latencia de peticiones, no se consigue ingestar un mínimo de peticiones por segundo, etc.
Concluyendo
Hay lugares donde este tipo de pruebas son muy relevantes por su contexto y forman parte del camino de entrega del software. En mi caso no han formado nunca parte de mi flujo habitual de trabajo, pero han habido ocasiones en las que me han resultado muy útiles para lanzar nuevos servicios, nuevas funcionalidades o para introducir cambios relevantes en la arquitectura con una mayor confianza.
Aunque nunca hay que olvidar que, como cualquier prueba automática, estas pruebas pueden ayudar a minimizar el riesgo pero no garantizan la ausencia total de problemas de degradación o errores. Ya que el tráfico artificial nunca será igual al generado a partir del comportamiento real de las personas que utilizan nuestro software, así que es importante invertir primero en observabilidad y en comprender cómo se comportan nuestros sistemas de software en producción.
Picando Código
Family 76 en 1
marzo 28, 2024 09:44
Estoy seguro que hay personas que al leer el título de este post le viene un recuerdo muy específico a la cabeza. En mi infancia (fines de los 80 en adelante, les aviso si en algún momento me empiezo a sentir adulto y la declaro por terminada), era muy común el Family, un clon del Nintendo Family Computer, o “Famicom” en Japón y Nintendo Entertainment System (NES) en América y Europa. Conocía muy poca gente que tenía un NES, pero incluso esas personas generalmente tenían un adaptador para jugar cartuchos de Family.
Se conseguían cartuchos de Family en todos lados, eran muy comunes y baratos, y parte de lo lindo era que venían en distintos colores y diseños. Los cartuchos de Family que se conseguían en Uruguay (y probablemente gran parte de América Latina) eran todos pirata. Y esto era lo normal para nosotros. Las consolas venían en distintas formas y tamaños, y su calidad era muy variable. No era raro haber tenido varios Family cuando uno de ellos caducaba. Incluso en las revistas (no oficiales) de videojuegos como Action Games se promocionaban clones del Family:

Publicidad Family – Bit Argentina
Había muchos cartuchos de un sólo juego (me acuerdo de tener Gremlins 2 y The Simpsons: Bart vs. the Space Mutants, entre otros). A veces los cartuchos eran el juego que anunciaban, roms originales. Otras veces incluían hacks de juegos que variaban los sprites o textos. No era raro encontrarse con “Super Mario 5” o “Street Fighter III” años antes de que se empezara a trabajar en dicho título. O juegos de Sonic en Family, donde reemplazaban el sprite del protagonista en algún otro juego de plataformas con el carpincho azul. Y cómo olvidar el Kunio-kun no Nekketsu Soccer League etiquetado como “Goal III”.
También existían los cartuchos de compilaciones x en 1, donde x era un número mayor a 2 con límite tendiendo a infinito. Muchas veces nos tocaba algo ridículo como “4999 en 1”, donde en verdad había unos pocos juegos, y cada página nueva del menú era un hack de estos juegos. Seguramente estos roms se modificaban programáticamente, alterando partes aleatorias del Rom, y consiguiendo resultados de calidad variables. La escena de romhacking para Family y NES explotaba en los 90’s. Supe tener varios de estos cartuchos, creo que en uno de ellos se incluía una sóla versión de Contra que era la versión completa sin modificar del juego de NES.
Cada tanto nos tocaba uno muy bueno. Recuerdo tener una colección con 6 o 7 juegos de deportes de pelota, por ejemplo. Pero el cartucho que recuerdo con más cariño era mi 76 en 1. Se trata de una colección de 76 juegos únicos. Seguramente el cartucho más jugado en mi(s) Family(s). Con él conocí clásicos del NES como Pinball, Excite Bike, Twin Bee, Popeye, los títulos de Donkey Kong, Karateka y tantos más. Este fue el cartucho en el que jugué Super Mario Bros. por primera vez (experiencia de la que escribí en esta entrada). Y otros títulos que no sé qué tan conocidos son pero me llenan de nostalgia como Antarctic Adventure, Road Fighter, City Connection y más. Con este cartucho aprendí las reglas del deporte Baseball, jugando Baseball de Nintendo
Incluye la versión de Tetris que crecí jugando y recuerdo ver a mi madre jugar cada tanto (cuando no jugaba Galaga). En el NES existieron dos versiones de Tetris: una por Nintendo y otra por Tengen. Tengen era una empresa de Atari, que publicó juegos autorizados y no autorizados por Nintendo, su historia es bastante interesante. La versión de Tetris que desarrollaron para NES no estaba licenciada y tras una demanda de Nintendo, tuvieron que retirarla del mercado. Pero además de ser técnicamente superior a la versión de Nintendo, se convirtió en la versión de Tetris más pirateada e incluida en este tipo de colección pirata.
En mi cabeza, “la canción del Tetris” era Bradinsky. Esta canción también se incluía en el port (oficial) a Arcades de Atari. Me acuerdo la gracia de tratar de hacer coincidir el ruido de la caída de una pieza con el ritmo de la canción. En esta versión de Tetris basé los colores de las piezas en mi Tetris. Más adelante me familiaricé con la canción más popular de Tetris, Korobeiniki, en el Game Boy, pero el Tetris con el que crecí es el de Tengen.
A continuación una representación gráfica de cómo recuerdo mi cartucho. Definitivamente no es la misma tipografía, ni la misma imagen de Pac-Man, aunque estoy casi seguro que en la etiqueta había un Pac-Man estilo caricatura. Tampoco estoy muy seguro si las imágenes de los juegos que se muestran eran las mismas, pero ahí va mi intento basado en imágenes encontradas por Internet:

Aproximación de memoria de cómo creo que se veía mi cartucho de Family “76 en 1”
Resulta que descubrí que este cartucho 76 en 1 es “conocido” en la escena bootleg:
The Supervision 76-in-1 is a multicart containing 76 games, made by Supervision in 1990 and credited to Tsang Hai on the menu.
El Supervision 76-in-1 es un multicartucho conteniendo 76 juegos, hechos por Supervision en 1990 con crédito a Tsang Hai en el menú.
En el enlace se puede encontrar la lista de los juegos disponibles en la colección. Teniendo este cartucho, ¡no se necesitaba más!
Y si uno supiera dónde buscar ese tipo de cosas, se podría hasta encontrar en línea el ROM de esta colección. Incluso si uno tuviera un Analogue Pocket con un Core para emular juegos de NES y fuera capaz de conseguir ese ROM, uno podría revivir su infancia en dicha consola portátil. Es más, si uno tuviera un NES Classic Mini, y uno tuviera el conocimiento y la audacia para hackear dicho aparatito y agregar más juegos, uno sería capaz de revivir su infancia en un televisor moderno. Yendo más lejos todavía, uno podría adquirir uno de esos cartuchos flasheables y jugar esta colección en hardware real. Pero no estamos acá para hablar de piratería…
Mandé un video al grupo de chat de mi familia con un poco de gameplay de Tetris Tengen y la melodía “Bradinski” de fondo preguntando “¿Quién se acuerda de esta musiquita?” y mi madre y una de mis hermanas respondieron “Siiiii”.
Más allá de la discusión de si la piratería está bien o está mal, si no hubiera existido el Family y el acceso a estos cartuchos en regiones como América Latina, una generación entera de videojugadores no existiría hoy. Los cartuchos originales de NES costaban como USD 40 cada uno en Estados Unidos, mucho más caros importados en América Latina. Si bien no jugué todos los juegos de esta colección (Mahjong te estoy mirando  ), estamos hablando de más de USD 3.000 para acceder a estos juegos.
), estamos hablando de más de USD 3.000 para acceder a estos juegos.
Este cartucho fue un excelente inicio a mi historia con los videojuegos. No tengo idea dónde estará estos días, es probable que se haya perdido esa vez que el Family se prestó a otra familia con todos los juegos. Pero agradezco a las personas que trabajan archivando y manteniendo la historia de los videojuegos que me permitirían revivirlo si yo fuese capaz de encontrar ese ROM, descargarlo y jugarlo. Qué lindo volver a encontrarme con 76 en 1.
El post Family 76 en 1 fue publicado originalmente en Picando Código.proyectos Ágiles
Modelo mental #1 – El diamante de la autonomía – auto-organización – ownership
marzo 13, 2024 05:00

- No puede haber compromiso sin ownership.
- No puede haber ownership sin autonomía.
- No puede haber autonomía sin propósito compartido, competencia y perímetro de actuación.
- Hace falta DESARROLLAR a la gente y CONFIAR en ella.
Este modelo mental se encuentra explicado en las imágenes de más abajo y en el siguiente vídeo: https://youtu.be/n7d6lJY5_ps?t=2743
Para que la autonomía de una persona o un equipo funcione, es necesario considerar varios aspectos:
- Tener un objetivo compartido, unas expectativas acordadas entre ambas partes, que sean factibles.
- Unas competencias que permitan que se dé esa autonomía, lo cual implica que el desarrollo de las personas en la organización (a nivel personal y profesional) sea algo clave. Y esto no se trata solamente de formación, es cuestión de dar oportunidades, acompañar, ofrecer feedback constructivo cuidando a la persona, etc.
- Unas restricciones o límites claros (tiempos, recursos, principios, directivas o valores [E.g. Esto aquí NO lo hacemos tratando mal a la gente]).
- La información necesaria para poder tomar buenas decisiones (a veces no se comparte lo suficiente y se acaba haciendo algo que no aporta lo suficiente). Tiene que estar fácilmente disponible, comunicada todas las veces que haga falta hasta que llegue y se entienda, suficientes conversaciones alrededor del tema con las personas relevantes e impactadas, …).
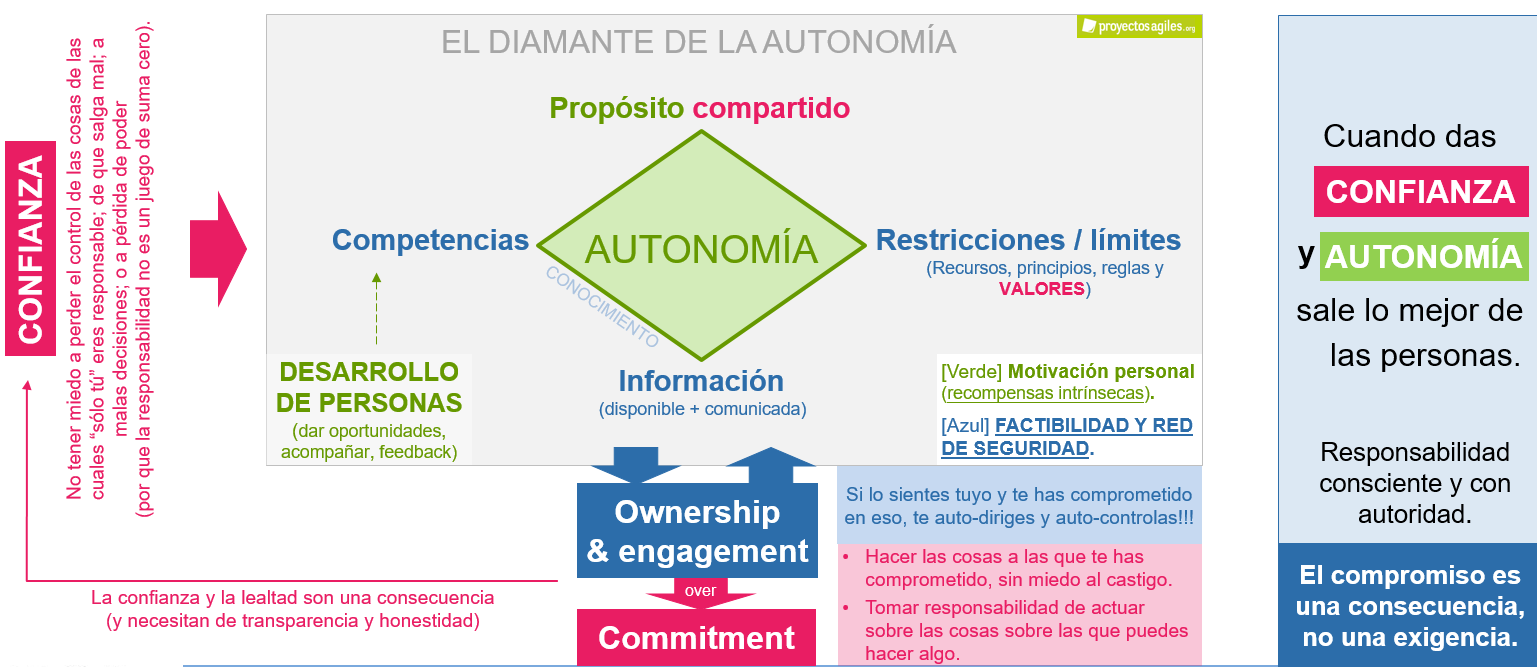
¿Cuántas veces hemos tenido problemas por no tener alguno de estos ámbitos suficientemente claros o trabajados?
Todo esto permite que la gente esté motivada y tenga más compromiso (es una consecuencia, no una exigencia), pasar del empoderamiento a las personas al “ownership” por parte de las personas, movilizar la inteligencia colectiva y que puedan avanzar con confianza si aparecen problemas, creando un círculo virtuoso de confianza mutua en la organización (y, al contrario, no hay que crear sistemas de trabajo que impliquen un castigo por el error).
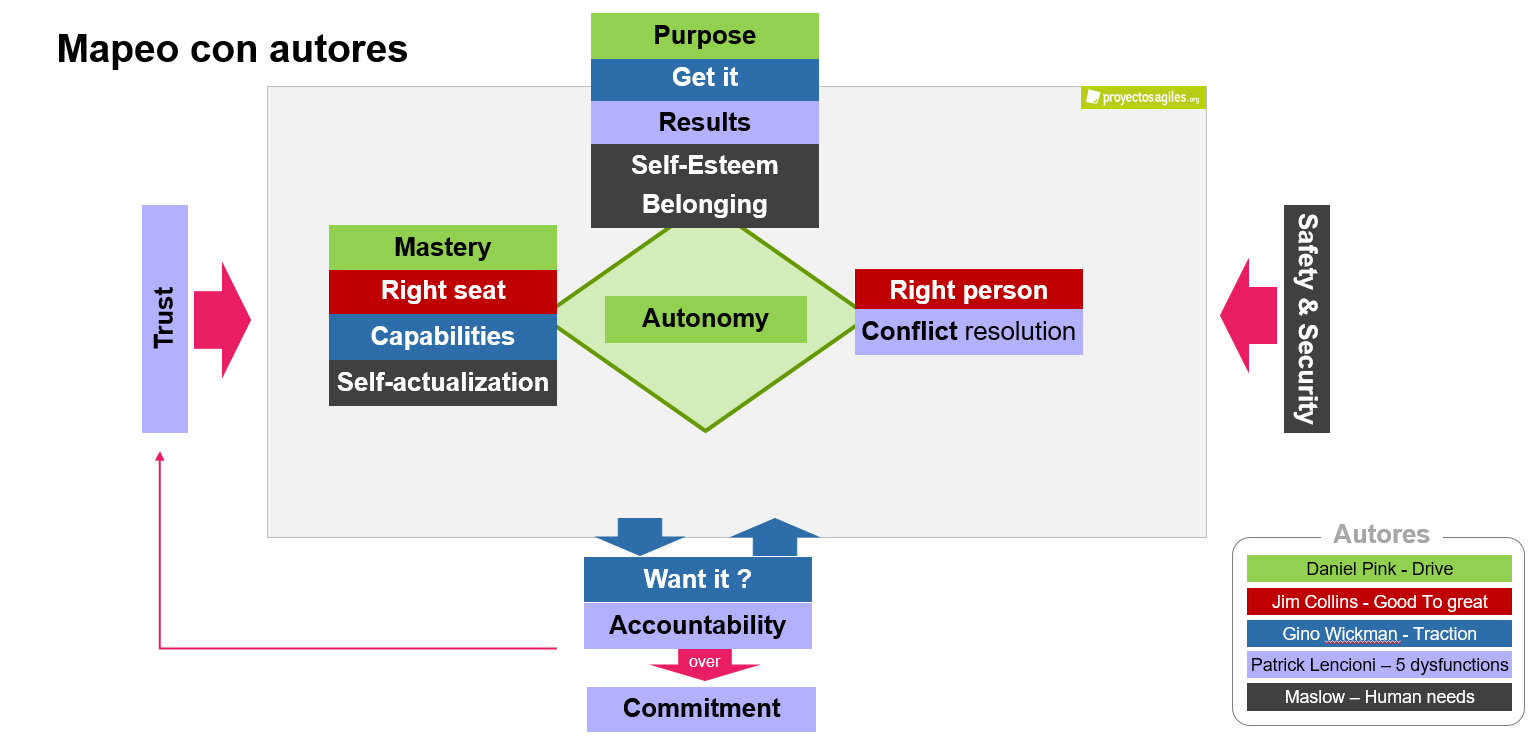
Este modelo mental se puede utilizar en un workshop con un equipo o con managers. La idea es ir explicando paso a paso el modelo mental (mejor si es con una pizarra blanca en función de las aportaciones del grupo), con preguntas («¿que creéis que es necesario para…?», «¿Alguna vez os ha pasado …?», «¿Cuándo habéis visto que esto funciona y por qué?»). De este modo entre los asistentes se genera una conversación de aprendizaje: van explicando cómo ven el modelo, se cuentan historias sobre lo que les ha sucedido, que les ha funcionado (o no), cómo el contexto ha influido, etc. De este modo se enseñan unos a otros, ya que cada persona es capaz de percibir los modelos desde ángulos diferentes.
Modelos mentales:
- Modelo mental #1: AUTO-ORGANIZACIÓN / AUTONOMÍA Y OWNERSHIP.
- Modelo mental #2: GESTIÓN POR MIEDO VS CREAR UN ENTORNO SEGURO.
- Modelo mental #3: FEEDBACK AGRESIVO O PASIVO VS CLARIDAD, SINCERIDAD Y RESPETO.
Artículos relacionados
Picando Código
Programando Tetris con DragonRuby
marzo 11, 2024 04:30
En octubre de 2016 me dispuse a aprender a programar videojuegos con Ruby usando la biblioteca Gosu. Siempre me gustó el juego Tetris y me pareció un buen ejemplo como primer proyecto. Es relativamente simple como para llegar al punto de declararlo “terminado” sin sentirme abrumado. En el proceso, podía aprender lo suficiente de las herramientas como para tener una idea mínima para arrancar algo nuevo.
Todavía tengo el código que escribí en ese momento. No es buen código, pero dado que lo escribí para experimentar y aprender, no lo juzgo tanto. Conseguí recursos gráficos libres de internet, y en menos de 200 líneas de código logré esto:
No es gran cosa, pero en su momento me voló un poco la cabeza poder mover piezas con un gamepad y ver que el código que había escrito se traducía en cosas tan gráficas. Acostumbrado a tanta programación backend y web, esto era novedoso. Si bien había experimentado con PyGame y otras cosas antes de esto, me animaba la idea de programar con un lenguaje que me gusta y conozco tanto como Ruby. De todas formas, el experimento no pasó mas de eso.
Mi historia con el desarrollo de videojuegos siguió de forma bastante infrecuente. Recientemente hice un par de cursos con Godot, que me parece una herramienta genial para desarrollar videojuegos, y poca cosa más. Pero siempre mantuve el tema en la cabeza y hasta empecé un cuaderno donde voy anotando ideas de cosas que se me ocurren para desarrollar en juegos.
En algún momento de mi carrera me enteré de la existencia de DragonRuby, otra biblioteca para desarrollar videojuegos con Ruby. Amir Rajan, el fundador y uno de los desarrolladores de DragonRuby, publicó un juego hecho con DR en Nintendo Switch. El hecho de que pudiera usar Ruby y éste último dato me motivaron para conseguir una licencia. Teniendo las herramientas, era cuestión de tiempo que me pusiera a aprender a usarlo y empezara a desarrollar mis juegos, ¿no? Bueno, sí, pero demoré un rato.
DragonRuby no es gratuito, pero tiene un precio bastante accesible y se vende a precio de descuento muy frecuentemente (algunas veces se consigue gratis por alguna promoción o game jam). Encima de eso, hay muchos factores que permiten obtener una licencia gratuita: ser menor de 18 años, estudiante de cualquier tipo, quieres enseñar a alguien a programar, y más. O simplemente se puede escribir un correo electrónico a Amir explicando por qué quieres una licencia gratis y te la va a otorgar.
Amir tiene la costumbre de usar una frase “now build a game dammit” (algo así como “ahora crea un juego maldición”). Cada vez que leía esta frase, ya fuera en el Discord del proyecto o en Mastodon, me sentía un poco mal… Un día que tuve libre en el trabajo recientemente decidí poner en uso esa licencia de DragonRuby que había obtenido hace tiempo, y hacer un juego. Había visto que Ryan C. Gordon (@icculus) – desarrollador de SDL, portador de muchos juegos a Linux, entre otras cosas- tenía un tutorial para desarrollar Tetris con DragonRuby. Así que ese dichoso día me fijé el objetivo de seguir el tutorial, y lo conseguí. Ya tenía los recursos gráficos de mi primer intento con Gosu, era hora de darle vida a una versión más de Tetris.
Programar con DragonRuby fue sumamente divertido. Me hizo acordar por qué me resultaba tan divertida la programación, algo que no me pasaba desde hace bastante tiempo. Por primera vez en muchos años, volví a quedarme despierto hasta tarde programando. No tengo la más mínima idea de programación de videojuegos. No conozco los patrones, o las buenas prácticas y tenía básicamente cero experiencia. Se me ocurre algo que quiero que pase en el juego, y tengo que pensar de cero cómo se podría implementar en el contexto del framework. Esto me forzó a pensar en soluciones totalmente nuevas para mí, expandir mi creatividad y salir de mi zona de confort. Esa sensación de descubrimiento y resolución de problemas me resultó casi como una droga!
DragonRuby tiene unos principios fundamentales atados a GTK:
- El juego corre en una función principal
- que se ejecuta 60 veces por segundo
- y tiene que decirle a la computadora qué dibujar cada vez
El “Hola Mundo” de DragonRuby se ve así:
def tick args
args.outputs.labels << [580, 400, '¡Hola mundo!']
end
Esa función se va a ejecutar 60 veces por segundo (¡60fps!), así que hay que programar todo en relación a eso y ese paradigma es totalmente distinto a lo que acostumbro a programar. La lógica del juego, los menúes, interacciones y demás, van todo por esos 60 ticks por segundo. Una vez que esto hace clic en la cabeza, se empieza a pensar en relación a eso y ya las ideas van mutando a formas de implementarlas en base al tick.
Empecé a usar mi cuaderno donde anotaba ideas (y apuntes de cosas que aprendía) para desarrollo de videojuegos como agenda. Inicialmente le agregué algunas cosas simples al juego base del tutorial:
- Niveles - Cada 10 líneas se sube de nivel, lo que acelera un poco la caída de las piezas.
- Apariencia - El tutorial nos enseña cómo dibujar sólidos en la pantalla, que los cambié por sprites que conseguí en OpenGameArt, así como el fondo y otros detalles más. La animación inicial de los bloques del título en base a funciones matemáticas me divirtió mucho!
Prácticamente todos los días desde que empecé el proyecto dediqué aunque sea unos minutos después del trabajo o antes de acostarme para agregarle al código. Fui agregando varias cosas más: Pantalla de inicio con menú de opciones, efectos al hacer dobles, triples o tetris, pausar el juego, créditos, ayuda, pantalla completa opcional, y más ajustes. Corregí unos errores de colisión, aunque hay un bug todavía al momento de rotar piezas que necesito arreglar.
Para la música, usé el editor de música de GB Studio, un entorno de desarrollo de videojuegos para Game Boy. La breve melodía que se escucha al iniciar el juego es el resultado de aprender a usar la herramienta con ensayo y error en unos minutos, metiendo las notas a mano de oído hasta tener algo relativamente aceptable. La canción deja que desear, pero probablemente en algún momento le dedique algo más de tiempo como para tener una versión más decente de Korobeiniki, la canción folclórica rusa en la que está basada el tema de Tetris.
DragonRuby hace súper fácil la publicación en itch.io, así que agregué a mi cuenta el perfil de "desarrollador" y subí mi versión de Tetris en este enlace. Empecé con el nombre "Picando Tetris", pero no tengo idea si eso podría traerme problemas por usar un nombre registrado. Otras versiones tuvieron el nombre código "Picandotris", hasta que un amigo me sugirió "Fertris" (Fernando's Tetris!) y ahí quedó porque nombras cosas es difícil. Se puede descargar gratis para Linux, RaspberryPi, Mac OS y Windows. Si la llegan a probar, cuenten qué tal anduvo.
El resultado final se ve algo así:
No creo que comparta el código porque si lo ve un desarrollador de videojuegos profesional me va a mandar preso. Hablando en serio, es un código para experimentar y aprender y no creo que nadie más que yo pueda beneficiarse mucho de él.
La experiencia de agregarle cosas al Tetris de icculus queda, y además de haberme divertido, es una de las tantas cosas que aportan a mi experiencia como programador. Pero por sobre todo, ¡me divertí! Si ya sabes Ruby y te interesa, te recomiendo leer más sobre DragonRuby y empezar a hacer juegos. Y si bien ya no me voy a sentir mal cada vez que lea a Amir pidiendo que haga juegos, todavía tengo que arrancar uno propio de cero. La parte más difícil de Tetris es la lógica del juego, y eso lo hizo todo icculus en este ejemplo. Además Amir ya me dijo "seguí haciendo juegos maldición", ¡ya vendrán otros proyectos!
Siempre me ha interesado la idea de desarrollar mi propio videojuego, pero no sé si cambiaría mi carrera como para dedicarme a eso a tiempo completo. Es un tema que me interesa mucho, y me fascinan los distintos procesos creativos que se involucran: programación, diseño, arte, sonido. Pero sí me encantaría poder publicar varias de las ideas que tengo como videojuegos en algún momento. El tiempo que pasé programando y experimentando con DragonRuby se me pasó volando. Así que por lo menos para mantener esa sensación de programar cosas divertidas, espero seguir desarrollando juegos como pasatiempo.
El post Programando Tetris con DragonRuby fue publicado originalmente en Picando Código.Picando Código
Mar10: El Día de Mario mirando películas de Mario
marzo 10, 2024 11:49
 Con motivo de Mar10 (10 de marzo, “Día de Mario”), hoy volví a mirar las películas de Mario. No se pueden comparar entre sí por varias razones: La película de 1993 no tenía más que unos pocos títulos con poco o nada de historia en la que basarse. Además fue pionera en su género, no se sabía qué funcionaba en la transición del videojuego al cine, y es una película totalmente experimental. Ni que hablar que Nintendo le dió ruenda suelta a Hollywood con los personajes, y no se involucró prácticamente en la producción. La película de 2023 tiene 30 años de juegos, spin-offs y demás legado de dónde sacar ideas. Además contó con la producción de Shigeru Miyamoto y el involucramiento directo de Nintendo.
Con motivo de Mar10 (10 de marzo, “Día de Mario”), hoy volví a mirar las películas de Mario. No se pueden comparar entre sí por varias razones: La película de 1993 no tenía más que unos pocos títulos con poco o nada de historia en la que basarse. Además fue pionera en su género, no se sabía qué funcionaba en la transición del videojuego al cine, y es una película totalmente experimental. Ni que hablar que Nintendo le dió ruenda suelta a Hollywood con los personajes, y no se involucró prácticamente en la producción. La película de 2023 tiene 30 años de juegos, spin-offs y demás legado de dónde sacar ideas. Además contó con la producción de Shigeru Miyamoto y el involucramiento directo de Nintendo.
Son dos productos completamente distintos, pero disfrutables a su manera, y una gran parte de la historia de los hermanos Mario.
Super Mario Bros. (1993)

Super Mario Bros. (1993)
La primera película live-action basada en un videojuego no fue bien recibida ni por la crítica ni por el público general. Es la primera vez que vuelvo a mirarla después de no sé cuántos años. Está bueno que la puedo ver con una perspectiva totalmente nueva. No sólo no me acuerdo, sino que mis gustos y expectativas han ido cambiando con el tiempo. En su momento seguramente la haya visto en el cine, y si no recuerdo mal, tenía las figuras de acción de Mario, Luigi y un Goomba de la película en mi arsenal.
Mientras la miraba, varias veces me surgió la pregunta “¿para quién es esta película?”. Tiene sus partes más “familieras” (escenas que llaman a un estilo de película como “Home Alone”), y otras un poco más adultas. Los extras del Blu-Ray respondieron la pregunta. Incluyen unos videos con entrevistas donde varias de las personas responsables hablan sobre el proceso unos cuantos años después. Tuvo un montón de problemas de producción: el guión fue re-escrito varias veces, el enfoque iba cambiando casi que todo el tiempo y unos cuantos problemas más. Esto explica que a veces parece enfocada a niños pero también muestra cosas que alguien esperaría de una película noventera para adultos.
La trama es absoluamente desquiciada, pero podría haber funcionado muy bien. Con la influencia de Super Mario World, Mario y Luigi viajan a una dimensión paralela donde los dinosaurios siguieron evolucionando en paralelo con los mamíferos hasta llegar a ser básicamente humanos reptilianos. Su ciudad es una Manhattan distópica con estética cyberpunk. El arte es muy bueno, tanto la magia que hicieron transformando la planta de cemento abandonada donde filmaron, como el maquillaje, los efectos especiales y demás. El diseño de las armas que usan para “desevolucionar” en la película está basadao en el Super Scope. Las bob-ombs son bombas a cuerda con dos piecitos que se asemejan mucho a las de Super Mario Bros. 3 o World con un “product placement” en sus zapatos muy chiste de película noventera. Creo que estas dos piezas de utilería son los dos únicos aspectos fieles al videojuego.
Pero la fidelidad no importa. Con la edad y la experiencia uno aprende a entender que el mundo de las películas es alternativo al material en el que están basadas. Y si no nos gusta, la podemos ignorar y volver a disfrutar del material original. Hay que disfrutarlas como una nueva interpretación basada en personajes. Con esa idea ya asimilada, realmente quise que me gustara más. Pero la mata el guión. Si hubiera tenido un guión mejor escrito, más cohesivo y con buenos diálogos, podría ser excelente. Bob Hoskins y John Leguizamo están muy bien interpretando a Mario y Luigi. Yoshi es un dinosaurio hecho con efectos prácticos realista con un resultado en pantalla excelente, unos días antes de que se estrenara Jurassic Park. Y en general la historia podía haber dado para una secuela tranquilamente.
La idea es totalmente alocada, y podría haber funcionado mucho mejor. Pero ahí quedó como un producto de su época y problemas de producción. Si no fuera por la siguiente película de Mario que voy a comentar y su éxito, no descartaría que con la falta de ideas que está teniendo Hollywood en los últimos tiempos, no se hiciera un reboot de esta idea en particular. Que sería igual de desquiciado, pero igual la miraría.
¿Recomiendo verla? Sí, si tienen un domingo donde no pueden salir por alguna razón, es entretenida para pasar el tiempo. Por lo menos nos quedó esta tremenda versión de “Walk the Dinosaur” y una escena bajando por un túnel congelado con este temún de Joe Satriani…
Super Mario Bros 2023
Avanzamos 30 años y tenemos una de las películas de videojuegos más entretenidas hasta el momento. Donde la anterior tenía unas pocas referencias a cosas del videojuego, en ésta casi cada personaje, nota musical, o escenario es una referencia directa a algún juego de Mario o de Nintendo. Incluso se transforma en una cacería encontrar cada detalle que se relaciona a algún juego de Mario o Nintendo. Habiendo crecido jugando Super Mario y juegos de Nintendo, disfruté de cada una de las que encontré, así como los guiños y homenajes de todo tipo. Se rumorea que hasta hay Pikmins escondidos por ahí…
La historia no es demasiado profunda, pero es entretenida y la plataforma para introducir el mundo y los personajes a la audiencia y contar varios chistes, aparte de promocionar juegos. Nintendo reportó vender muchas copias nuevas de juegos de Mario en Nintendo Switch gracias al éxito en taquilla. También se muestran coss que potencialmente podrían dar para contar más historias, pero las irán dejando para las secuelas, que la primera ya está anunciada (más información al final de este post).
Desde el momento en que se anunció, venía renegando con Chris Pratt como Super Mario porque el tipo hacía la misma voz en todas sus películas. Pero la verdad que mirándola no me doy cuenta y se me pasa. Dejando de lado eso, la selección de actores para las voces me parece muy bien. Charlie Day como Luigi, Anya Taylor-Joy como Peach, Charles Martinet -que estoy seguro crearon el personaje sólo para que esté  - y demás actores están muy bien con sus personajes. De destacar Seth Rogen como Donkey Kong, elección inesperada que pega muy bien y que no sólo hace su contagiosa risa característica sino que canta el DK Rap. Y para mí la estrella más grande es Jack Black con su interpretación de Bowser y la canción “Peaches”, que no puedo evitar escuchar en mi cabeza cada vez que paso por la sección de frutas de un mercado y veo la palabra escrita. La estrella cínica de Mario Galaxy se lleva muchos aplausos y risas también por su humor negro.
- y demás actores están muy bien con sus personajes. De destacar Seth Rogen como Donkey Kong, elección inesperada que pega muy bien y que no sólo hace su contagiosa risa característica sino que canta el DK Rap. Y para mí la estrella más grande es Jack Black con su interpretación de Bowser y la canción “Peaches”, que no puedo evitar escuchar en mi cabeza cada vez que paso por la sección de frutas de un mercado y veo la palabra escrita. La estrella cínica de Mario Galaxy se lleva muchos aplausos y risas también por su humor negro.
Se aprecia cariño y conocimiento del material original, pero es lógico asumiendo que seguramente más de una de las personas involucradas hayan crecido jugando Nintendo. Los avances en animación también dan lugar a escenas de acción muy buenas que se traducen de manera excelente del videojuego al cine y evocan distintas etapas de la vida de un jugón como uno pegado al televisor. La música acompaña muy bien, tanto interpretaciones orquestrales de melodías que tenemos quemadas en el cerebro por pasar tantas horas jugando Nintendo, como canciones más populares. Como ejemplo una escena con un tema de Bonnie Tyler es genial y la canción la enriquece mucho.
Si les gusta Super Mario, seguramente ya la hayan visto, y si no, recomiendo que lo hagan. La miré en el cine cuando salió y me divertí mucho. Tras verla de nuevo casi un año después en Blu-Ray, volví a disfrutarla y se mantiene siendo una de mis tres películas preferidas del año pasado (las otras dos son Barbie y Godzilla Minus One). Tendré que volver a mirarla el 10 de Marzo de 2025 si no tengo nada mejor que hacer o poco antes que se estrene la secuela para refrescar la memoria.
Noticias sobre Mario en su día
Hoy Nintendo publicó un video donde Shigeru Miyamoto comenta que están trabajando junto a Illumination en la secuela de la película animada de Super Mario Bros. Se espera que esté disponible en Estados Unidos y otras regiones el 3 de abril de 2026. En el mismo video se confirman fechas de disponibilidad de algunos juegos de Mario para Nintendo Switch este año:
- Paper Mario: The Thousand-Year Door – 23 de mayo, 2024
- Luigi’s Mansion 2 HD – 27 de junio, 2024
- Dr. Mario (Game Boy), Mario Golf (Game Boy Color) y Mario Tennis (Game Boy Color) disponibles a partir del 12 de Marzo en Nintendo Online.
Bueno, me voy a jugar un rato a Super Mario Bros. Wonder y me acuesto a dormir…
El post Mar10: El Día de Mario mirando películas de Mario fue publicado originalmente en Picando Código.proyectos Ágiles
Master en Agile – MMA 2024-2025
marzo 10, 2024 11:55
En octubre de 2024 se iniciará el Barcelona la 14ª edición del Postgrado en Métodos Ágiles (PMA) y otra del Máster en Transformación Agile (MMA) en La Salle (Universitat Ramon Llull), el primero a nivel mundial sobre Agile.
El Máster en Métodos Ágiles de La Salle-URL va dirigido a profesionales que ven en las metodologías ágiles la mejor manera de adaptar rápidamente sus productos en entornos complejos y altamente competitivos, reduciendo el Time To Market de los mismos a fin de maximizar el valor aportado al negocio.
El Máster te permitirá desarrollar actitudes y capacidades para crear equipos de alto rendimiento con Scrum, Kanban, Design Thinking, Lean Startup para ajuste rápido de producto al mercado y te proporcionará herramientas y estrategias para escalar Agile en la organización, transformar su cultura y así conseguir mayor Business Agility.
Esta es una oportunidad única para aprender de profesionales-profesores de primer nivel, con muchos años de experiencia específica en Agile, aplicando principios y métodos ágiles en contextos diversos, especializándose en aspectos concretos, investigando sobre nuevas técnicas, ponentes en conferencias nacionales e incluso internacionales, que incluso han inventado métodos y escrito libros.
El MMA incluye las siguientes certificaciones oficiales:
- «Certified Scrum Master» (CSM) de la Scrum Alliance, la entidad de certificación Agile de mayor prestigio a nivel internacional.

- Certified Project, Portfolio, And Operations Management for Business Agility de Businessmap, creadora de la herramienta Kanbanize.

- Certified Agile Skills – Scaling 1 de la Scrum Alliance, , la entidad de certificación Agile de mayor prestigio a nivel internacional.

Adicionalmente, se incluye la visita a las siguientes empresas:

A continuación, más detalle acerca del Postgrado en Agile (PMA) y del Máster en Agile (MMA)
Para inscripciones, consultar la página oficial del Máster.
PMA – Postgrado en métodos Ágiles
El PMA incluye las siguientes certificaciones oficiales:
- «Certified Scrum Master» (CSM) de la Scrum Alliance.
- Opción de acceder al Certified Project, Portfolio, And Operations Management for Business Agility de Businessmap.
| Asignaturas | Temas | Profesores |
| Fundamentos & Inception | Principios y métodos más conocidos (Scrum, Lean, Kanban y XP). Facilitadores e impedimentos.
Inception y conceptualización ágil de proyecto, priorización ágil, historias de usuario, elaboración de Product Backlog, técnicas de priorización. | Silvia Sistaré
|
| Scrum y Kanban | Estimación y planificación ágil, framework de Scrum, retrospectivas, Kanban, métricas ágiles, herramientas ágiles físicas, radiadores de información. | Raul Herranz
|
| Personas y equipos | Gestión de personas, gestión de conflictos, motivación e incentivos, facilitación compartida, contratación ágil.
Visual thinking. | Steven Wallace
|
| Gestión de producto ágil | Design Thinking, Lean UX & Prototyping. Estrategia de Producto – Consciencia situacional (Wardley Maps), modelo de negocio (Lean Canvas), modelo de tracción, métricas AARRR. Customer development – Lanzando y escalando startups ágiles, las tres fases de un producto. Lean Startup – Desarrollo de producto basado en prototipos y experimentos. Bancos de ideas, desarrollo basado en hipótesis. | Laia Montaño Lucía Barroso |
| Ingeniería ágil | User eXperience y prototipado en Agile.
ALM ágil, eXtreme Programing, Software Craftsmanship, testing ágil. BDD y TDD. Desarrollo guiado por pruebas (de aceptación y unitarias). Métricas Accelerate y SW Delivery assessment. Cómo trabajar con código heredado y reducir la deuda técnica. | Laia Montaño
|
| Trabajo Final de Postgrado | Durante el Postgrado se realiza un caso práctico de introducción de los contenidos en un equipo ágil en una empresa real. Para ellos los alumnos se organizan en equipos multidisciplinares utilizando Scrum, con feedback regular de un tutor con experiencia en transformación de equipos. |
El Postgrado tendrá una duración de 4 meses y se realizará viernes tarde y sábado por la mañana.
Ver también:
- Mejora de la situación laboral los alumnos del PMA tras un año
- Principales aspectos valorados por los alumnos del PMA
MMA – Master en Métodos Ágiles
Incluye todas las asignaturas del Postgrado (PMA) y, adicionalmente, las siguientes asignaturas especializadas en Business Agility, agilidad organizacional y transformación (aparte de las tres certificaciones indicadas al inicio y las visitas a empresas):
| Asignaturas | Temas | Profesores |
| Enterprise Learning & personal efficiency | Agile Kaizen, Comunidades de Práctica, Open Spaces, Talent development, gamification. Productividad y aprendizaje personal en Agile (eficiencia). | Steven Wallace Olga Vela |
| Lean Thinking & Agile Management | Lean. Escalado con Kanban.
Visual Management Framework (VIMA – Agile para cualquier área – Fuera de tecnología). Agile-Lean Management | Teodora Bozheva
|
| Coaching y Cultura | Coaching de equipos, creación de equipos de alto rendimiento, liderazgo.
Tipos de cultura empresarial, gestión del cambio organizativo. | Joserra Díaz
|
| Transformación Continua | Estrategia de despliegue de Agile en organizaciones, cómo vender Agile a la Dirección. Contratos ágiles. Enterprise continuous improvement. Enterprise software development, Team Topologies & DevOps. | Xavier Albaladejo
|
| Scaling Agile | Escalado (LESS, Spotify, Nexus, SAFe, Unfix), desescalado y auto-organización empresarial (reinventing organizations, sociocracy 3.0, liberating structures, …), equipos distribuidos.
Impact Mapping, Product Portfolio Management, Roadmapping, Budgeting for Agile | Adrian Perreau Fernando Palomo
|
| Trabajo Final de Máster | Durante el Máster se realiza un caso práctico de introducción y aplicación de Agile en una empresa real, incluyendo la parte de transformación organizativa, de métodos y de cultura. Para ellos los alumnos se organizarán en equipos multidisciplinares utilizando Scrum, con feedback regular de un tutor con experiencia en transformación organizativa. | Xènia Castelltort (oratoria / public speaking para poder explicar tus ideas de manera convincente) |
El Máster tendrá una duración de 8 meses y se realizará viernes tarde y sábado por la mañana (incluye los estudios indicados en el Postgrado).
El cambio en la organización comienza por el propio cambio, para también poder dar ejemplo. Por ello en el MMA se realizan diferentes ejercicios de auto-conocimiento:
- Cómo el alumno trabaja en equipo.
- Estilo de liderazgo del alumno (según el paradigma Agile).
Como en las últimas ediciones, contaremos con la participación de empresas que nos explicarán sus experiencias de transformación y donde trabajan con modelos de gestión desescalados (basados en Sociocracia, NER y otras alternativas).
Información adicional
- Perfil de los estudiantes: 30-45 años (no son recién licenciados, son personas con experiencia profesional).
- Alrededor del 50% son mujeres.
- 15% de los estudiantes ya no son del ámbito tecnológico, son pioneros-innovadores en otras industrias.
- Alumnos de diferentes disciplinas – Product Owners, Scrum Masters, Agile Coaches, líderes de equipos, Project Managers, managers funcionales, ingenieros SW. Van a adquirir conocimientos de Agile “on-top” de todo eso (y a aprender unos de otros).
- Lo que les caracteriza: todos son agentes de cambio en su contexto (equipo, área, empresa).
- Sus 20 profesores (de reconocimiento internacional) son el MAYOR VALOR DIFERENCIAL del PMA y del MMA.
Testimoniales
Me ha permitido tener conocimientos sobre varios temas súper importantes dentro de la Transformación Digital. Me dio herramientas para crecer a Agile Coach y, además, para tener mejores conversaciones y discusiones con las empresas en donde he trabajado
Carolina Graffe
Estoy desplegando el TFM en mi empresa, Además, no estoy sola. Uno de mis compañeros del equipo ha sido contratado como consultor por mi empresa para darnos soporte. Así que no sólo estoy aplicando lo que yo aprendí, sino que el MMA me ha permitido ampliar mi círculo de contactos relevantes, que me permite seguir aprendiendo.
Susana Santillán
Estoy trabajando como agente del cambio y mis aportaciones son muy valoradas por mi jefe y compañeros. Por el feedback recibido, mis aportaciones están muy por encima de lo esperado para mi rol.
Robert Avellaneda
Tengo mucho más contexto y más herramientas para el día a día. Incluso a nivel personal también me está ayudando mucho
María Hachero
Además de los conocimientos concretos que se reciben, uno de los principales cambios que han experimentado los alumnos es mayor perspectiva en los problemas, cómo abordar la complejidad en las empresas, en su trabajo y en las relaciones entre personas y en equipos. Han ganado discurso y aplomo para defender de manera más objetiva propuestas de cambio y mejora.
Encuesta 2023 a alumnos de las ediciones anteriores:

(*) Las personas que han valorado el impacto como «neutro o poco» usualmente son perfiles muy especializados en contextos muy estáticos, con lo cual les es difícil cambiar de «profesión» e introducir cambios en sus organizaciones (aunque algunos de ellos incluso dan conferencias sobre cómo van avanzando en esos contextos tan singulares).
Picando Código
Publicado Gleam v1.0.0
marzo 08, 2024 11:00
Esta semana se publicó la versión 1.0.0 del lenguaje de programación Gleam, un “lenguaje amigable para hacer sistemas que escalan con tipado seguro”. Ya he escrito sobre Gleam en el blog antes, pero no he escrito tanto código como hubiera querido. Es uno de los tantos lenguajes que me gustan y con los que me gustaría programar más. Gleam cuenta con “el poder de un sistema de tipado, la expresión de la programación funcional, y la seguridad del entorno de ejecución tolerante a fallas y de alta concurrencia de Erlang, con una sintaxis moderna y familiar”.

El 4 de marzo Louis Pilfold, su creador, publicó esta primera versión “estable” del lenguaje, lo que describe como un gran hito para el ecosistema. En el anuncio escribe:
¿Qué es Gleam?
Gleam es un lenguaje de programación que intenta hacerle el trabajo de quienes escriben y mantienen sistemas de software lo más predecible, libre de estrés y disfrutable posible.
El lenguaje es consistente y tiene un área de superficie pequeña, haciendo posible aprenderlo en una tarde. Acompañado de una falta de magia y una fuerte intención de tener una sóla manera de hacer las cosas, Gleam es típicamente fácil de leer y entender. Leer y debuggear código es más difícil que escribir código nuevo, así que optimizamos para esto.
Gleam tiene un análisis de tipos estáticos robusto y un sistema de tipos inspirado en lenguajes como Elm, OCaml y Rust, así que el compilador sirve de asistente de programación, dándote contexto adicional para ayudarte a hacer el cambio que quieras hacer. No te preocupes por escribir código perfecto de primera, con Gleam refactorizar es de bajo riesgo y bajo estrés así puedes continuar mejorando tu código mientras aprendes más sobre el problema que estás resolviendo.
Ejecutar y administrar software es tan importante como escribirlo. Gleam corre sobre la máquina virtual de Erlang, una plataforma madura y probada que habilita a muchos de los sistemas más confiables y escalables del mundo, como WhatsApp. Gleam también puede ejecutarse en entornos JavaScript, siendo posible ejecutar código Gleam en el navegador web, en dispositivos móviles o en cualquier otro lado.
Gleam se ve así:
import gleam/json
import gleam/result.{try}
import my_app/person
import wisp.{type Request, type Response}
pub fn handle_request(req: Request, ctx: Context) -> Response {
use json <- wisp.require_json(req)
let result = {
use data <- try(person.decode(json))
use row <- try(person.insert(ctx.db, data))
Ok(person.to_json(row))
}
case result {
Ok(json) -> wisp.json_response(json, 201)
Error(_) -> wisp.unprocessable_entity()
}
}
¿Qué incluye Gleam v1?
Esta versión cubre todas las API públicas del repositorio git principal de Gleam:
- El diseño del lenguaje Gleam
- El compilador Gleam
- La herramienta de compilación de Gleam
- El gestor de paquetes de Gleam
- El formateador de código de Gleam
- El servidor de lenguaje de Gleam
- Las herramientas del compilador para JavaScript y el API WASM.
La biblioteca estándar Gleam y otros paquetes que son mantenidos por el equipo central obtendrán una publicación v1 en breve. Antes de publicarlas, vamos a estar haciendo pull requests a paquetes populares de la comunidad para relajar sus limitaciones de versionado en el gestor de paquetes para asegurarnos que la actualización a la V1 sea lo más sencilla posible para todos los usuarios de Gleam.
¿Qué significa V1?
La versión 1 es una declaración sobre la estabilidad y disponibilidad de Gleam para ser usado en sistemas en producción. Creemos que Gleam es adecuado para usar en proyectos que importan, y Gleam va a poveer una fundación predecible y estable.
Gleam sigue el versionado semántico, así que es prioridad mantener compatibilidad hacia atrás. Vamos a estar haciendo todo el esfuerzo para asegurarnos que Gleam no introduzca cambios que rompan la compatibilidad hacia atrás. La excepción a esto es por problemas de seguridad y robustez. Si se descrube un bug crítico de esta naturaleza, nos reservamos el derecho de corregir el problema de seguridad, incluso si algunos programas estuvieran tomando ventaja del bug.
¿Qué sigue para Gleam?
Gleam es un lenguaje práctico con la intención de hacer cosas reales, así que nuestro foco para Gleam post-v1 va a estar dividido entre productividad para usuarios de Gleam y sustentabilidad para el proyecto.
Productividad para usuarios de Gleam
Además de no introducir cambios que rompan la compatibilidad, se va a evitar agregar demasiado al lenguaje para que no se convierta en un lenguaje más complejo y difícil de entender. Pretenden mantener la simplicidad, agregando características nuevas al lenguaje, pero de forma conservadora. Va a haber un foco en mejorar el servidor de lenguaje Gleam para mejorar la productividad. También se va a trabajar en las bibliotecas de Gleam, con un foco inicial en desarrollo de páginas y servicios web.
Otra de las prioridades es la documentación, con trabajo en tutoriales y guías para todo tipo de tareas en Gleam.
Sustentabilidad
Gleam es un proyecto comunitario sin apoyo de una corporación. Louis es el desarrollador principal y trabaja en el lenguaje a tiempo completo, junto a voluntarios part-time concentrados en trabajo con impacto y sentido para la comunidad. Van a continuar también el trabajo en la documentación interna para que sea fácil para más gente colaborar con el proyecto.
Un tema importante es la sustentabilidad financiera. Louis trabaja a tiempo completo en el proyecto gracias a los sponsors en GitHub. Cuentan con un sponsor principal, Fly.io, que provee gran parte de los fondos. Pero están buscando diversificar la financiación del proyecto con más sponsors corporativos y otras vías de ingreso.
Mascota
El anuncio cierra presentando a Lucy, la nueva mascota del proyecto, así como mejoras en el sitio web gleam.run.
Instalación
Podemos instalar Gleam siguiendo esta guía. Personalmente vengo usando asdf para gestionar versiones de Gleam y algunos otros lenguajes de programación. Teniéndolo instalado, podemos gestionar las versiones de Gleam en nuestro sistema agregando el plugin:
Una vez instalado asdf y el plugin de gleam, podemos ejecutar lo siguiente para empezar a usar esta nueva versión:
$ asdf global gleam 1.0.0
$ gleam -V
gleam 1.0.0
Y con esto ya podemos empezar a programar en Gleam. Hay mucha información en la documentación, incluyendo guías de referencia viniendo de otros lenguajes.
El post Publicado Gleam v1.0.0 fue publicado originalmente en Picando Código.Picando Código
10 años de emacs.sexy
marzo 05, 2024 10:30
Esta semana se cumplen 10 años desde que registré el dominio y publiqué el sitio web emacs.sexy. Se ve que 2014 fue un año bastante ocupado en cuanto a proyectos personales…
En su momento escribí en el blog al respecto en Emacs es Sexy. Como comentaba originalmente, el sitio surgió como respuesta a vim.sexy, pero con un objetivo un poco más productivo: Con la disponibilidad de los nuevos TLD .sexy, hace poco salió en La Internet el sitio vim.sexy. Tiene pinta de ser una respuesta paródica al editor de texto hipster del momento Atom. Pero mi problema era: Si bien es una parodia graciosa, vim.sexy no aporta mucho (en mi humilde opinión). Supuse que alguien habría hecho algo similar para Emacs, por la eterna relación entre Emacs y Vim. Al ver que no era así, registré el dominio e intenté crear un sitio que sumara un poco más. En el mismo tono humorístico creé una página web más constructiva, con información sobre Emacs y con la meta de lograr motivar a alguna persona curiosa a probar y dejarse enganchar por Emacs.
Así que la idea es difundir y compartir Emacs y recursos para aprender a usarlo y más. Siempre tuve la idea de implementar un sistema multi lenguaje para poder publicarlo en varios idiomas, pero nunca le dediqué el tiempo necesario. ¡Algún día prometo tenerlo también en español! Tuve la suerte de que el sitio creció mucho gracias a aportes de mucha gente gracias a su naturaleza de código abierto, así que
El diseño cambió bastante y está mucho más moderno que el original gracias a la grande de Mery, la versión inicial se veía mucho más “hecha por un programador”:
Es interesante reflexionar sobre “el editor de texto hipster del momento” que comentaba en su momento. En 2014 era Atom. No sé si antes o después vino Sublime, y ahora un montón de gente se pasó a Visual Studio Code. Mientras estos editores van y vienen, Emacs y Vim los miran pasar. Hace años que uso Emacs y sigo aprendiendo cosas nuevas bastante seguido. De sólo pensar en tener que aprender una herramienta nueva para tener que editar texto o escribir código en un lenguaje de programación específico me estresa 
Así que si no conocen Vim, Emacs o Spacemacs (lo mejor de ambos mundos), les invito a entrar a al sitio y aprender un poco más. De repente aprenden una herramienta para toda la vida como vengo haciendo yo.
El post 10 años de emacs.sexy fue publicado originalmente en Picando Código.Blog Bitix
Configurar GNU/Linux para usar forward DNS y el servidor DNS de Consul
febrero 24, 2024 04:00
Una de las cuestiones que tenía pendiente de mirar sobre Consul es como hacer que un nodo con GNU/Linux pueda acceder al catálogo de servicios mediante la interfaz DNS que ofrece Consul. Para esto es necesario configurar el forward DNS.
Blog Bitix
Obsidian, una herramienta para almacenar conocimiento
febrero 10, 2024 06:00
Hace ya unos meses desde que estoy usando Obsidian, pasado este tiempo considero que es un salto a los anteriores editores y aplicaciones de notas que he estado usando. A nivel personal como diario y otros asuntos ofrece varias funcionalidades que facilitan el gestionar el conocimiento y que no he visto en los anteriores editores que he usado. Es más que un editor de texto es una herramienta para almacenar conocimiento.
Arragonán
Buscando el Product Market Fit y Arquitectura Hexagonal
enero 23, 2024 12:00
Hace un par de meses estuve en La Vertical by Mercadona Tech hablando sobre DDD estratégico. Al final del evento, pude conocer a algunas personas con quienes estuve compartiendo impresiones, ideas, proyectos…
En un momento dado, una persona me preguntó sobre qué opinaba de usar el estilo de arquitectura de Ports & Adapters, más popularmente conocida como Arquitectura Hexagonal, cuando el contexto es la fase de búsqueda o consolidación del Product Market Fit. Me pilló la pregunta algo a contrapié y creo que le respondí de forma un poco tibia; podríamos resumirlo con un clásico: “No lo sé, creo que depende del equipo y del contexto“.
Esto es algo sobre lo que he compartido mi punto de vista en petit comité en bastantes ocasiones, así que quería extender un poco esa respuesta aterrizándolo en este artículo.

¿Product Market Fit?
Este es el momento en el que un producto no está validado a nivel de negocio, o al menos no totalmente. Son momentos donde aún no es rentable y hay que probar a lanzar soluciones para cubrir los problemas de nuestros potenciales clientes e ir iterando (o descartando) esas soluciones. Más info sobre esto en este artículo de la lista de correo de Ignacio Arriaga: ¿Qué es el product market fit y cómo acelerarlo?.
Así que en una situación en la que no hemos consolidado el Product Market Fit, la capacidad de iterar un producto de software a una velocidad razonablemente alta es crítica para hacerlo. Más en situaciones en las que tenemos un presupuesto limitado, como suele ser el de la mayoría de startups.
¿Arquitectura Hexagonal?
Si seguimos el estilo de Hexagonal Architecture o Ports & Adapters o Clean Architecture, colocamos en el medio nuestra lógica de negocio y nos abstraemos de los detalles de implementación de infraestructura.
Esta infraestructura son tanto los driver ports que son el mecanismo de entrega para interactuar con la lógica de negocio, como podrían ser server-side rendering, REST, gRPC, GraphQL, CLI, tareas programadas… Como los driven ports que son los encargados de mantener el estado vía persistencia de datos y la comunicación hacia otros sistemas.
Las características principales de este estilo de arquitectura son la cambiabilidad de la infraestructura y, como consecuencia de eso, la testeabilidad. Ya que al utilizar inyección de dependencias nos abstraemos de las diferentes piezas de infraestructura y podemos testear la lógica de negocio de forma unitaria.
Frente a lo que me parece percibir a veces, no hay una forma única de implementar software con este estilo de arquitectura. En mi caso, ha evolucionado un poco mi forma de trabajar con este enfoque, pero como base siguen siendo bastante válidos los contenidos que compartimos en algunas charlas de hace algunos años con Coding Stones.
Lo malo
Este estilo de arquitectura se ha popularizado mucho en los últimos tiempos y ha crecido de la mano con el uso conjunto de los patrones tácticos de DDD. Tanto que para muchas personas creo que no hay diferencia, no se percibe que son cosas distintas que unas veces se complementan y otras no tiene demasiado sentido aplicar, al menos no de forma purista.
Así que esto en ocasiones lleva a sobreingeniería en el diseño, en forma de exceso de abstracciones y aumento de complejidad extrínseca, haciendo un código más difícil de modificar y extender funcionalmente. Lo que provoca que en esos casos de aplicaciones con una lógica de dominio no demasiado compleja, se ralentice la velocidad de iteración en el producto.
También, otras veces, se espera que al aplicar este estilo de arquitectura desaparezcan todos los problemas asociados a la deuda técnica. Como si ya vineran integrados mágicamente en ello principios como DRY, YAGNI, KISS, Separation of concerns, ley de Demeter, las 4 reglas del diseño simple… y nos fuera a evitar tener code smells.
Lo bueno
Para mí, lo que aporta este tipo de arquitectura en este tipo de contextos es principalmente la testeabilidad. Cuando se quiere iterar rápido, tener una batería de tests en la que puedas confiar y que se ejecuta rápido es una gran ayuda para mantener el foco en lo que estás desarrollando.
En segundo grado, la cambiabilidad nos aporta que podemos posponer decisiones, por ejemplo, usando soluciones de infraestructura a priori simplistas que nos permitan validar que se aporta valor a pequeña escala, sabiendo que de ser necesario, podemos cambiarla en el futuro con menos esfuerzo al no afectar al diseño.
Depende del equipo y del contexto
Sobre el contexto, empiezo desde una situación en la que se ha llegado a la conclusión de que no podemos servirnos de herramientas no-code ni de un prototipo o prueba de concepto que podamos tirar a la basura dentro de pocos meses. Así que no nos quedan más narices que desarrollar algo que pueda evolucionar, iterarse y adaptarse a lo que nos vayamos encontrando en el futuro.
Normalmente en estos casos seremos un equipo pequeño, con capacidad financiera limitada tanto para contratar como para subcontratar y donde querremos tener buena capacidad para entregar software. Porque, de lo contrario, difícilmente podremos iterar nada.
Cualquier decisión técnica para mí debería ir encaminada a usar soluciones conocidas siempre que sea posible. En general, creo que la línea a seguir es la de Choose Boring Technology, con más razón en el caso de estar consolidando el Product Market Fit.
Algunas preguntas que podemos hacernos para pensar sobre esto: ¿Quiénes formamos parte del equipo? ¿Cuánto hemos trabajado usando el estilo de arquitectura de Ports & Adapters? ¿Nuestro software tiene un dominio con cierta complejidad o se parece más a CRUD que encajaría bien acoplado con algún framework? ¿Tenemos algún framework de desarrollo con el que todas las personas del equipo seamos productivas? ¿Sabemos o hemos comprobado si estaremos peleando contra ese framework si lo combinamos con ese estilo de arquitectura? …
Alternativas
En algunas ocasiones, mi aproximación ha sido quedarme un poco a medio camino, utilizando alguno de los artefactos o prácticas que habitualmente se asocian a la Arquitectura Hexagonal, pero manteniendo el acoplamiento al framework en cierto puntos. Esto es: capa de use cases para representar lo que hace el producto de software, inyección de dependencias para tener piezas cambiables y hacer que la lógica sea más fácil de testear y, si encaja con las necesidades iniciales del producto, también modelar eventos.
Use Cases
Esta capa representa las acciones que se pueden hacer sobre el producto de software. A partir de aquí, se encapsula lógica y se orquestan las llamadas a infraestructura. En esta capa no se sabe si va a ser llamada desde un API rest, un comando desde CLI, un cron…
En mi caso, normalmente son clases con constructor y un solo método público para ejecutarlas, así que en un momento dado hasta podrían ser funciones.
En caso de que usemos un ORM (o un ODM o similar), utilizo esas mismas entidades para representar el dominio. Al menos hasta el momento donde se percibe que el modelo de dominio y el modelo de datos entran en conflicto como para tener que hacer una separación.
Inyección de dependencias
En los constructores de los use cases, hago uso intensivo de inyección de dependencias, más para ganar en testeabilidad que en cambiabilidad de la infraestructura. Esto es que en lenguajes de tipado estático, en los constructores normalmente se espera la inyección de una dependencia de una clase y no de una interfaz. El esfuerzo que sí trato de hacer al inyectar esas clases a los use cases, es no acoplarme a nivel de naming de clases y métodos sobre la implementación.
En algunas ocasiones, esta inyección la he mantenido manualmente y otras a través de algún framework de IoC, dependiendo principalmente de si el framework de desarrollo lo trae de serie o si la base de código es aún manejable sin ello.
Eventos (opcional)
En casos donde desde el inicio se observa que existen muchos side-effects en un producto tiendo a introducir eventos de dominio, seguramente no para todos los use cases, pero al menos sí los más relevantes. Pistas para introducirlos pueden ser necesidades relacionadas con: auditoría, distintos tipos de notificaciones, desacoplar la comunicación con otros módulos o sistemas, instrumentar behavioral analytics en el backend, etc.
Conclusiones
El mero hecho de usar o no Ports & Adapters no es relevante para que el producto tenga éxito, pero la capacidad de iterar rápido el producto es crítica.
Dentro de que nunca vamos a tener certezas, en momentos donde estamos buscando Product-Market fit a nivel técnico normalmente deberíamos ir hacia lo más seguro y conocido por parte del equipo. Bastantes riesgos existen en esos contextos como para asumir más.
Ya sea un estilo de arquitectura completamente acoplado a un framework, de Ports & Adapters o se quede en algún punto intermedio para desarrollar un producto de software, lo que considero innegociable para iterar rápido es acompañarlo de otras 3 prácticas técnicas:
- Hacer testing automático, al menos unitario y de integración de forma bastante intensiva para tener confianza en los cambios y poder iterar más rápido.
- Tener automatizado el pipeline de entrega y que lo pueda hacer cualquiera en el equipo, ya sea pulsando un botón o con un push en el sistema de control de versiones.
- Preparar un mínimo de telemetría técnica y de producto, para saber de forma temprana si han surgido problemas en producción a partir de un cambio y poder analizar cómo es el comportamiento de quiénes están usando el producto.
Blog Bitix
Compro un soporte de monitor para ganar espacio en la mesa
enero 20, 2024 06:00
Finalmente he adquirido un soporte de monitor junto con unas bandejas para regletas y enchufes. Ha sido una gran mejora inmediata para ganar espacio y organización de mi mesa. Ahora tengo mucha más comodidad y una mesa en la que puedo dejar muchos más elementos si necesito para la tarea que realice. Un soporte de monitor es algo a comprar adicionalmente al monitor pero el espacio liberado en la mesa lo vale.
Navegapolis
¿Por qué le llaman Agilidad cuando quieren decir lo de siempre?
enero 17, 2024 11:56
Hay titulares que se pasan de frenada, como el del libro del mismísimo Jeff Sutherland: “Scrum: el arte de hacer el doble de trabajo en la mitad de tiempo“.
Llamativo y tentador, porque ¿Quién no desea cuadruplicar la productividad?
¿Por qué vender una idea equivocada de la agilidad?
¿Para vender más libros?
Es verdad que los equipos ágiles alcanzan niveles altos de productividad, calidad y creatividad, pero esta no es la finalidad de la agilidad, sino la consecuencia. La finalidad es crear ambientes de trabajo en los que las personas trabajen motivadas y comprometidas.
La agilidad es para los que quieren equipos que disfruten construyendo productos increíbles o brindando servicios de primera. Personas que encuentran plenitud en su trabajo, no sólo un cheque a fin de mes.
Querer las consecuencias de la agilidad —hacer el doble en la mitad de tiempo— sin un interés real en el desarrollo y plenitud de las personas acaba rompiendo la magia: la motivación y el compromiso. Es como querer una pareja para obtener su dinero, sus cuidados o sus favores.
La entrada ¿Por qué le llaman Agilidad cuando quieren decir lo de siempre? se publicó primero en Navegápolis.
Una sinfonía en C#
Cómo crear una imágen de Docker sin tener Docker instalado gracias a Azure
enero 16, 2024 12:00
Introducción
Todos nos hemos encontrado en la encrucijada de tener que crear una imagen de Docker y no tener Docker instalado en nuestro equipo. En este post vamos a ver cómo podemos crear una imagen de Docker sin tener Docker instalado en nuestro equipo utilizando una cuenta de Azure.
El problema
Primero necesitamos una cuenta de Azure y una instancia de Azure Container Registry a la que tengamos acceso. La idea es que teniendo el código o el binario, lo que queramos meter en la imagen (Sea lo que sea, multistae o no) y el Dockerfile podemos utilizar la capacidad de Azure Container Registry de crear una imagen a partir de un Dockerfile.
Importante, nuestro código o binario subirán a la nube durante el proceso
Entonces, teniendo ya el código o binario y el Dockerfile, vamos a crear la imagen.
Pasos para crear la imagen y subirla al ACR
Antes de nada tenemos que tener (además de la cuenta de Azure y el ACR) instalado el Azure CLI. Lo podemos descargar desde aquí
- Hacer login en Azure
- Seleccionar la suscripción donde tenemos el ACR
- Crear la imagen
az login
az account set --subscription KKKKKK-KKKK-KKKK-KKKK-KKKKKKKKK
az acr build --registry miurl.azurecr.io -f Dockerfile --image test:latest .
como vemos el comando acr build es idéntico al docker build, pero en vez de utilizar el contexto local, lo hace en la nube.
Y como dije antes, tomará un tiempo porque subirá el código o binario a la nube y luego creará la imagen.
Una vez que termine, podemos ver la imagen en el ACR.
Enjoy!
Blog Bitix
Hemeroteca #23
diciembre 22, 2023 05:00
Este complicado año 2023 termina con varios cambios en el blog y a nivel personal. El blog ha bajado en gran medida las visitas e ingresos por publicidad AdSense y en el que he dejado de publicar artículos con un calendario fijo semanal.
Juanjo Navarro
We're hiring!
noviembre 30, 2023 07:59
Genial esta parodia de una oferta de trabajo:
We work only with the very latest technologies, frameworks and languages. At least that’s what we claim and it doesn’t matter if there’s zero correlation to our actual product: […] It’s purely functional Web Assembly all the way to the core neural network running the heart of what’s essentially an imageboard with nicer design.
Our development toolchain is exclusively open source. This naturally doesn’t apply to our own product, because we love money. However, we do encourage all our employees to give back to the FOSS community – they just have to do it on their own free time. We’re not completely stupid.
Y sobre el proceso de selección:
A lengthy recruitment process which will take up significant amounts of your spare time, except for the interviews. We always interview on prem and during office hours.
IQ tests and bizarre questions designed to trap you in logical cul-de-sacs while simultaneously having nothing at all to do with programming or relevant domain-specific knowledge.
Meta-Info
¿Que es?
Planeta Código es un agregador de weblogs sobre programación y desarrollo en castellano. Si eres lector te permite seguirlos de modo cómodo en esta misma página o mediante el fichero de subscripción.
Puedes utilizar las siguientes imagenes para enlazar PlanetaCodigo:
![]()
![]()
Si tienes un weblog de programación y quieres ser añadido aquí, envíame un email solicitándolo.
Idea: Juanjo Navarro
Diseño: Albin
Fuentes
- Arragonán
- Bitácora de Javier Gutiérrez Chamorro (Guti)
- Blog Bitix
- Blog de Diego Gómez Deck
- Blog de Federico Varela
- Blog de Julio César Pérez Arques
- Bloggingg
- Buayacorp
- Coding Potions
- DGG
- Es intuitivo...
- Fixed Buffer
- Header Files
- IOKode
- Infectogroovalistic
- Ingenieria de Software / Software Engineering / Project Management / Business Process Management
- Juanjo Navarro
- Koalite
- La luna ilumina por igual a culpables e inocentes
- Made In Flex
- Mal Código
- Mascando Bits
- Metodologías ágiles. De lo racional a la inspiración.
- Navegapolis
- PHP Senior
- Pensamientos ágiles
- Picando Código
- Poesía Binaria
- Preparando SCJP
- Pwned's blog - Desarrollo de Tecnologia
- Rubí Sobre Rieles
- Spejman's Blog
- Thefull
- USANDO C# (C SHARP)
- Una sinfonía en C#
- Variable not found
- Yet Another Programming Weblog
- design-nation.blog/es
- info.xailer.com
- proyectos Ágiles
- psé
- vnsjava